Doris Segment V3 vs Parquet & Lance: Fixing Footer Metadata Explosion
How Parquet’s Flatbuffer proposal, Lance, and Doris segment v3 each tackle columnar footer explosion when wide tables push metadata from KB into MB.
Modern columnar formats were designed for tables with dozens of columns. Today’s CDP profiles, ML feature stores, and Variant-flattened logs routinely produce files with thousands. When that happens, the assumption that “the footer is small enough to read for free” stops holding — and the cost of reading two columns starts scaling with all C columns. This post walks through what that “metadata explosion” actually looks like, then compares how Parquet’s Flatbuffer proposal, Lance, and the new Doris segment v3 each tackle it under very different constraints.
TL;DR
- Wide tables, ML feature stores, and Variant fields push columnar footers from KB into MB, breaking the “footer is free” assumption that columnar formats were built on.
- Three knobs to fix a fat footer: change its encoding, physically split heavy parts out, and trim redundant fields. Each format picks a different combination.
- Parquet’s Flatbuffer proposal: an in-place engine swap that rides inside an extension slot in the old Thrift footer, so old and new readers stay interoperable across the ecosystem.
- Lance: 40-byte fixed footer, one protobuf per column, no row groups. Only possible because schema, indexes, and transactions live in upper layers.
- Doris segment v3: minimally invasive surgery — externalize
ColumnMetaPBto a CMO region and add a path secondary index for Variant sub-columns, while keeping every existing OLAP capability intact. - Same problem, three coordinate systems: who controls the readers, and whether the format is a thin container or a full OLAP segment, decides the design space far more than the technology does.
1. Starting from an Analytical Table
1.1 OLAP, columnar storage, and the workload we face today
If you build OLAP databases, this picture is familiar. Business systems write a stream of rows into a fact table every day. Data analysts, BI dashboards, and ML pipelines all run SQL against that table. The queries share a few traits:
- The table is wide (many columns), but a single SQL touches only a handful of them.
- Queries lean on aggregation and filtering (SUM, COUNT, GROUP BY, WHERE) and rarely do row-level point lookups.
- Data volumes are large, but access is skewed. Most columns and most rows in any single query go untouched.
Storage for this workload almost always picks a columnar layout: pack values from the same column physically together so unread columns cost nothing, then encode each column with whatever fits best (dictionary, bit-pack, RLE) to shrink bytes. Parquet, ORC, Doris segment, Lance, ClickHouse Wide part: they’re all variations on the same idea.
1.2 The read pattern of a columnar file
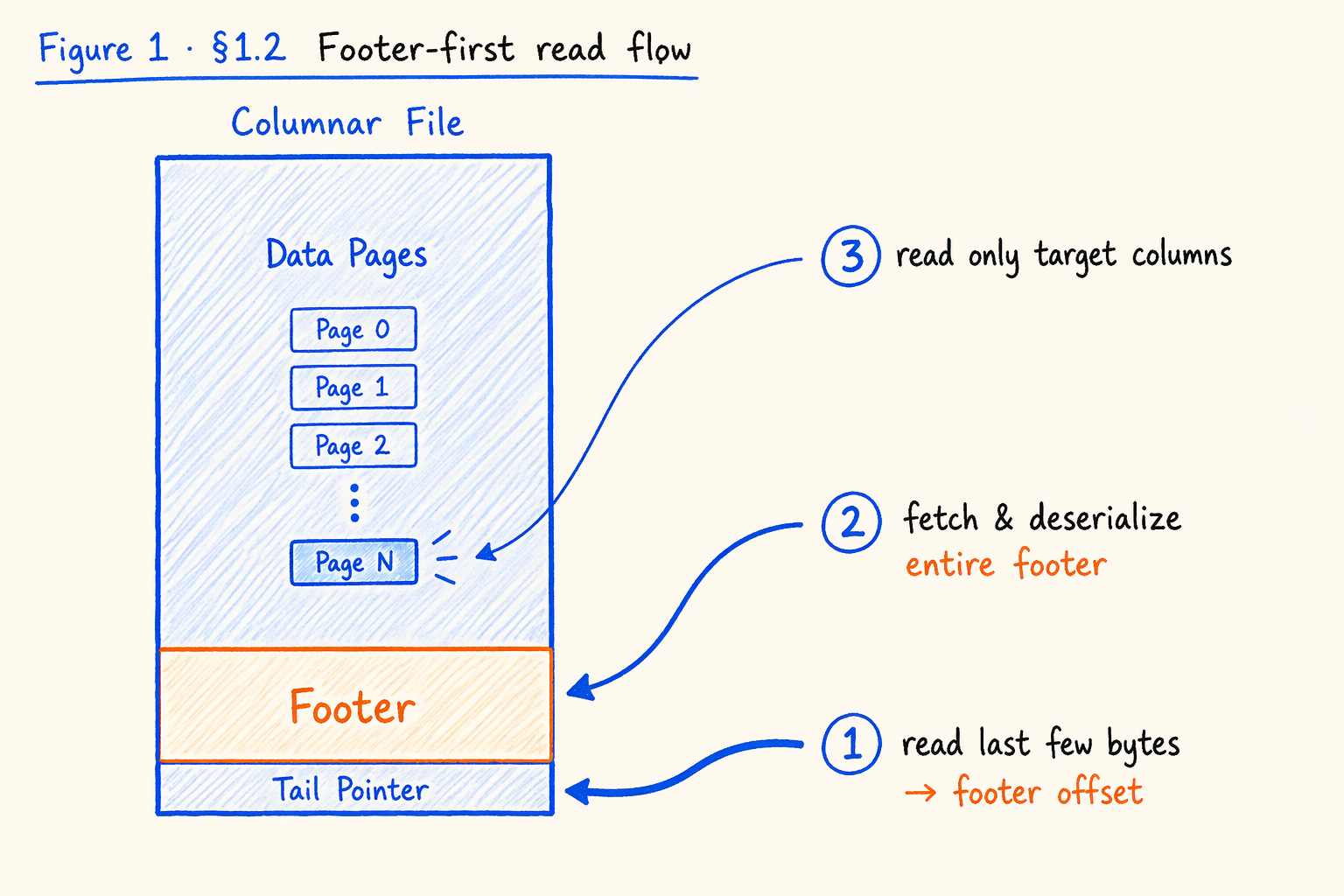 Figure 1.2 · Footer-first read flow: how a columnar reader reaches one column from a cold open.
Figure 1.2 · Footer-first read flow: how a columnar reader reaches one column from a cold open.
Once a table lands as columnar files on disk, an engine running SQL roughly walks through these steps:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
File tail (fixed structure)
↑
1. Read a few bytes at the tail to learn the footer's offset and length
↓
Footer
(centralized metadata)
↑
2. Pull the entire footer back, deserialize the whole thing,
and find: "where do my columns live in the file,
what encoding do they use, what min/max can I prune on?"
↓
Data Pages
(the actual column data)
↑
3. Read only the pages for those columns.
Other columns stay untouched.
This is the “footer-first” read pattern. It assumes one thing: the footer is small enough that reading and parsing it cost nothing worth measuring. As long as that holds, “read two columns, pay for two columns” actually works.
The assumption was fine when columnar formats were born (Parquet 2013, ORC 2013, early Doris segment). A fact table had dozens of columns and a few row groups, the footer was a few dozen KB, and against GB of data that was free.
Today’s workloads have left that era behind.
1.3 Why “tables with thousands of columns” are real
Thousand-column tables sound like a stunt. They aren’t. Three scenarios show up routinely in production today.
Scenario A: Wide user behavior tables / CDP. In consumer products, teams aggregate every user tag, attribute, and recent action into one “user profile” table. Each new initiative (campaigns, fraud, recommendations, support) bolts on dozens to hundreds of columns. After three years, profile tables with two or three thousand columns are normal. The same shape shows up in CDPs (Customer Data Platforms), advertising DMPs, and financial feature platforms.
Scenario B: ML feature tables / multimodal training data. Feature tables routinely store a 768- or 1024-dimensional embedding as that many columns. Add handcrafted features, statistical features, and rolling-window features, and the count crosses a thousand. Multimodal scenarios with image, text, and audio embeddings push it further. Lance was designed for exactly this shape.
Scenario C: Semi-structured logs / event streams / API payloads. Application logs, telemetry, and JSON pulled from third-party APIs have flexible schemas, lots of fields, and high sparsity. Storing the JSON as one string column makes querying painful. Modern columnar engines (ClickHouse Object/JSON, Doris Variant, Snowflake VARIANT, DuckDB STRUCT) split JSON into sub-columns by path automatically. A single complex event becomes hundreds or thousands of sub-columns. To the storage engine, sub-columns look almost identical to user-defined columns.
Put these together and the conclusion is plain: thousand-column tables are no longer a fringe case but a mainstream shape that emerged in the last few years. The “footer is small” assumption from 1.2 has not kept up.
1.4 A SQL that raises a question
Consider an ordinary SQL:
1
2
3
4
SELECT user_id, event_time
FROM events
WHERE dt = '2026-04-20'
LIMIT 1000;
Two columns from a 3000-column fact table. Intuitively, the IO cost should be roughly the bytes those two columns occupy. Put it on object storage with a real columnar file, though, and the picture usually goes:
- Bytes for column data: a few KB to a few dozen KB.
- Bytes for the footer (so you know where those two columns live, what encoding they use, what statistics they carry): a few MB to a few dozen MB.
- The footer doesn’t fit in one fetch. Object storage needs two or three round trips to pull it back.
- Once back, the entire footer must be deserialized. CPU time scales with all C columns, not the two you wanted.
- The query’s warmup gets eaten by the footer.
Swap events for an event table where a Variant field expanded into thousands of sub-columns and the footer balloons further. In the worst cases, column data is a few KB while the footer is dozens of MB. This metadata-versus-data inversion is not rare in production.
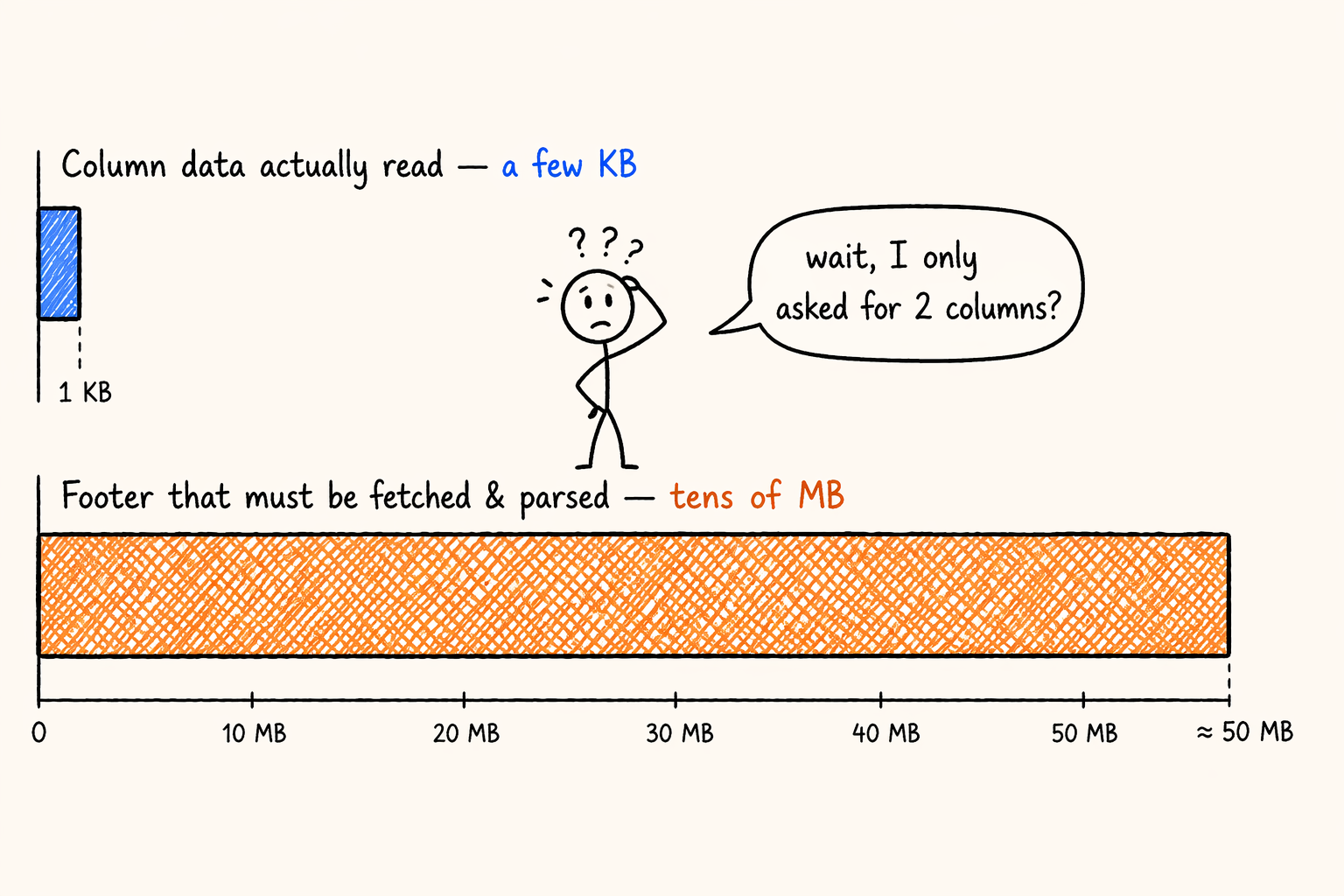 Figure 1.4 · Metadata vs data inversion: footer balloons past the actual column bytes.
Figure 1.4 · Metadata vs data inversion: footer balloons past the actual column bytes.
A natural question:
Why should the cost of reading N columns from a columnar file scale with all C columns?
2. The Nature of the Problem: What Is “Metadata Explosion”?
2.1 What’s actually in a traditional columnar footer
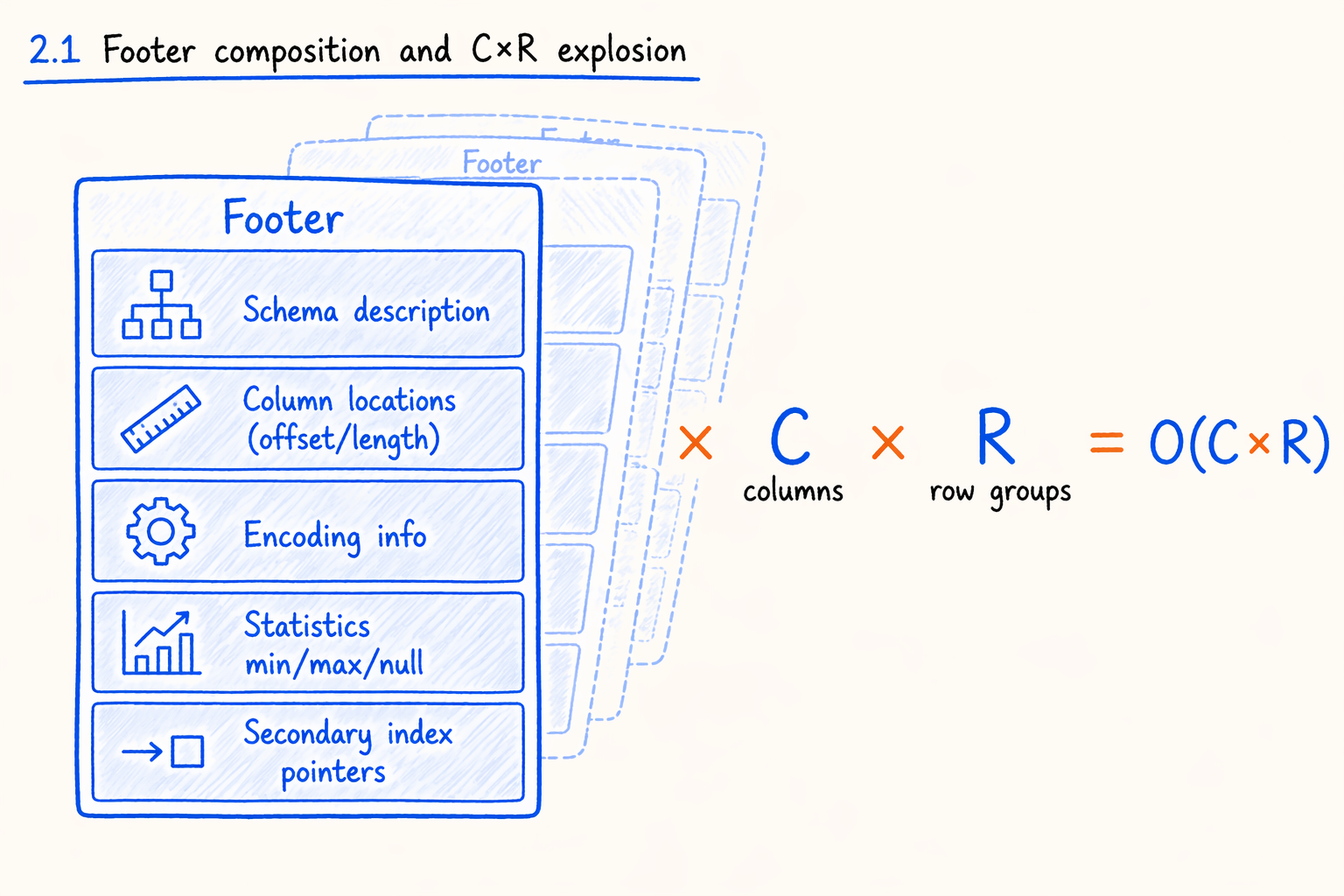 Figure 2.1 · Footer composition and the C × R explosion.
Figure 2.1 · Footer composition and the C × R explosion.
To see why the footer gets fat, look inside. A typical columnar footer (Parquet, ORC, and Doris segment all look similar) carries:
- Schema description: each column’s name, type, nesting structure, and nullability.
- Column locator information: byte offset and length for every column, every row group or segment, every page.
- Encoding information: dictionary, PLAIN, RLE, or bit-pack; whether compressed; what algorithm.
- Statistics (min, max, null_count, distinct_count) for predicate pushdown and partition pruning.
- Pointers to secondary indexes: offsets pointing at bloom filters, zone maps, bitmaps, and other index pages.
- Other metadata: row counts, version numbers, key/value extension properties.
Every entry above is “one per column.” A file with C columns carries C copies of each category in its footer. Split the file into row groups too and you multiply by R. So the footer’s size sits on the order of O(C × R).
When C and R are both small, no problem. Dozens of columns times a few row groups gives a footer of a few dozen KB. Once C climbs into the thousands and R into the dozens or hundreds, the footer grows from tens of KB to tens of MB.
2.2 The serialization format makes things worse
Footer size isn’t the only problem. Worse: the footer usually uses Thrift or Protobuf, and both decode sequentially. They’re variable-length, self-describing, and byte-compact, but they cannot jump to an arbitrary field in O(1). Reading one field means walking through every preceding tag and length. So even when SQL touches two columns, the parser still walks every column’s metadata, and CPU time scales with C × R.
2.3 Three faces of the pain
Combine the two and the chain reaction looks like this:
- Multiple IO fetches. Object storage caps the bytes per request. A footer past one fetch unit needs at least two round trips, sometimes preceded by a “size probe” call. Every extra round trip doubles end-to-end latency, and this is where cloud-native scenarios hurt most.
- Whole-footer CPU deserialization. No matter how few columns you query, the entire footer parses first. CPU time depends on the file’s total column count, not the query. In a distributed OLAP engine this segment shows up clearly in query startup latency.
- Wasted memory. Roughly 99% of the deserialized objects go unused, but the parser still allocates them, holds memory, and hands them to the GC. Pure dead work.
The painful part: all these costs are paid for the columns you didn’t read. Of the cost of reading N columns, the C - N share gets dumped on you. That violates the most basic premise of columnar storage, which is read on demand.
2.4 An example: Variant sub-columns in Doris segment v2
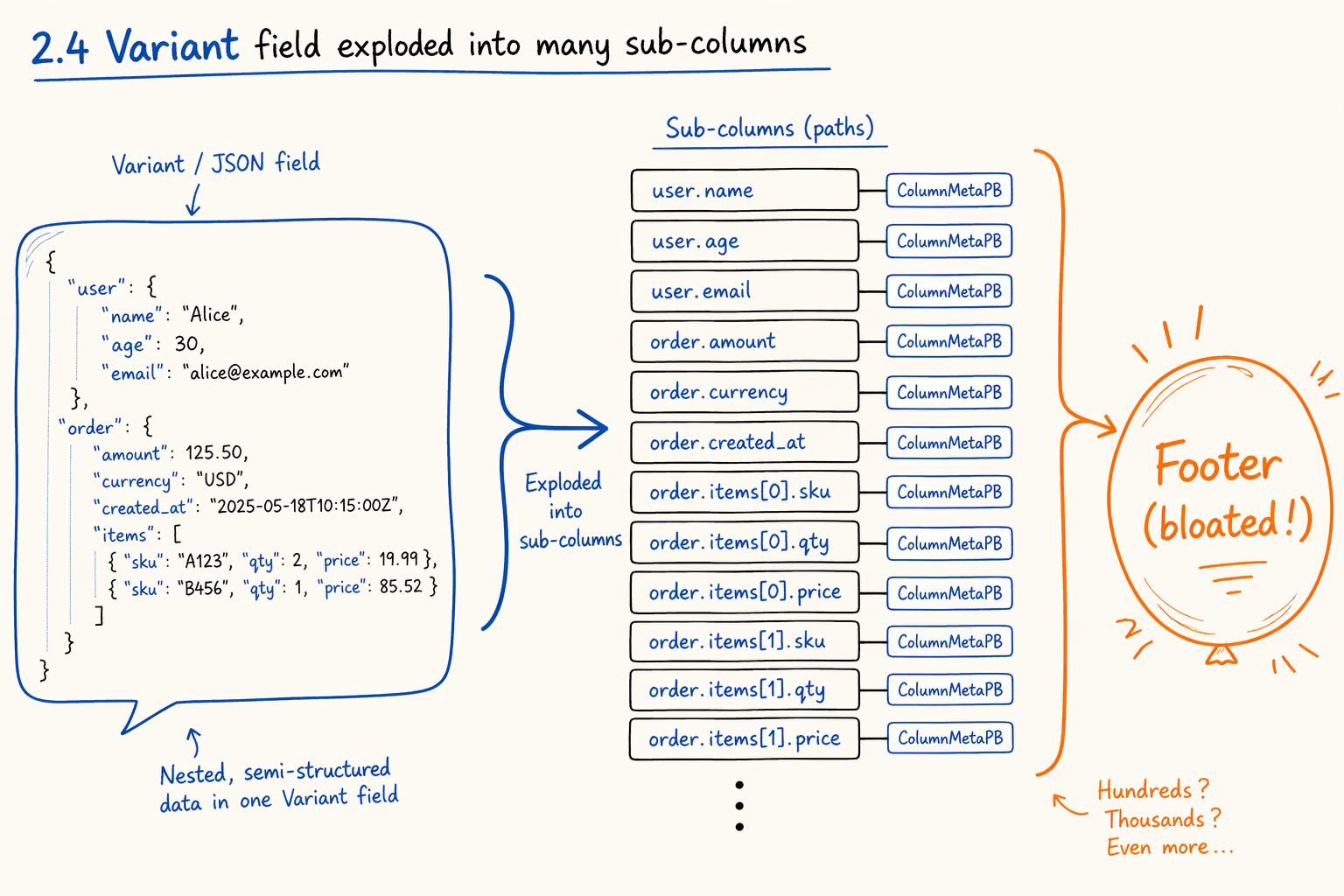 Figure 2.4 · A single Variant field exploded into many sub-columns inside the footer.
Figure 2.4 · A single Variant field exploded into many sub-columns inside the footer.
Enough abstraction. The columnar file format Doris used before 4.1, called segment v2, describes its footer with protobuf, simplified to:
1
2
3
4
5
6
message SegmentFooterPB {
optional uint32 version = 1;
repeated ColumnMetaPB columns = 2; // ← every column's metadata, inlined here
optional uint32 num_rows = 3;
// ... other fields
}
The second field is the issue. Every column’s metadata (page offsets, index positions, encoding info, statistics) sits directly in the footer. On a normal wide table this causes no problem, since column counts are bounded, each ColumnMetaPB is a few hundred bytes, and the footer fits in a few dozen KB.
Variant changes the math. On the write side, Doris splits a Variant field into many sub-columns by path, one regular sub-column per path. These sub-columns are first-class to the segment file, so each one’s ColumnMetaPB lands in footer.columns. A moderately complex JSON schema can grow the footer to dozens of MB.
The query path makes it worse. Even when a user only queries variant['user']['name'], no fast lookup exists. The parser deserializes every sub-column’s ColumnMetaPB, then linearly scans path strings to find the target. Every segment open repeats this.
V2’s pain is the trio in 2.3 detonating on Variant: the footer is too big to fetch in one trip, parse time scales with the sub-column count, and 99% of those sub-columns go unread on each query.
2.5 Summary
“Metadata explosion” in one sentence:
The problem isn’t that the file is big or the column data is large. The problem is that the metadata describing the columns swells with C × R, and drags IO, CPU, and memory on the read path down with it.
It’s a textbook case of a structure designed for narrow tables and small row groups failing in the era of wide tables, semi-structured data, and multimodal workloads. Over the last year or two, three independent open-source projects (Parquet, Lance, Doris) have taken the problem seriously. Each picked a very different path because each faces different constraints.
3. Viable Directions
Section 2 laid the problem bare. Engineering options for fixing it are narrow. Lay them out and only three knobs exist.
3.1 Three knobs
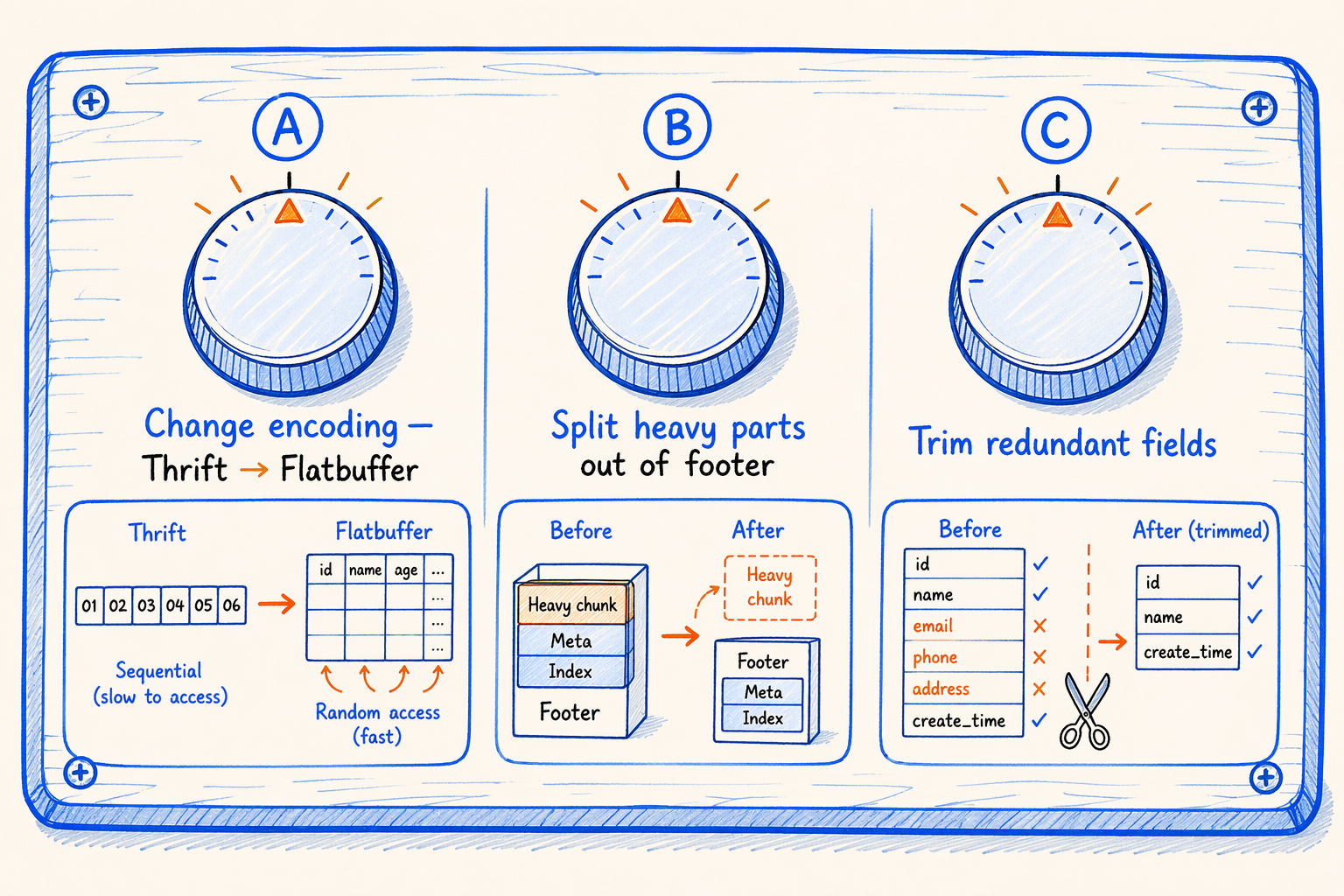 Figure 3.1 · Three knobs to fix a fat footer: encoding · split · trim.
Figure 3.1 · Three knobs to fix a fat footer: encoding · split · trim.
A. Change the footer’s encoding. Move from Thrift or Protobuf (which demand sequential decoding) to a format that supports O(1) field access (Flatbuffer’s vtable layout, or a fixed-length C struct). Even when the footer remains a single segment that must be read whole, CPU parsing drops from O(C × R) to O(C_r × R), where C_r is the columns actually accessed.
Cost: variable-length encodings (ULEB128, ZigZag) lose some byte-level compactness. You claw it back through layout choices.
B. Physically split the heavy parts out of the footer. The bulky categories (per-column page offsets, per-column statistics, per-row-group column index) move into a separate region of the file. The footer keeps only a directory pointing at them. Reading the footer means reading just the directory; the actual metadata gets fetched on demand.
Cost: writers add an organization step and pointer management; readers add an addressing step; per-column meta needs an extra IO (usually amortized by cache).
C. Trim the metadata itself. Delete or compact fields that “could be derived from elsewhere” or “were over-designed.” Examples: storing min/max as binary strings is wasteful for fixed-length types and should pick the right field per physical type; nested fields’ full paths can be derived from the schema and need not be stored per column; row group offsets capped at 2³¹ shrink from int64 to int32.
Cost: many of these fields exist for historical reasons. Removing them breaks backward compatibility, and the more aggressive the trim, the more painful the migration.
3.2 The real decider isn’t technology, it’s constraints
A, B, and C all stack in theory. Which knobs each project picks, and how far it turns them, isn’t a pure technical decision. Constraints matter more than technical detail. Two of them in particular:
- Can you control all the readers? When reader implementations sit in dozens of ecosystem projects (Spark, Trino, DuckDB, Polars, Iceberg, Delta, ClickHouse, each with its own Parquet reader), any change to the binary layout is meaningless without a network-wide upgrade. The same dynamic shapes other open-format evolution debates — see how hard it is to add an index to Iceberg for a parallel case where the ecosystem, not the technology, sets the ceiling. Under that constraint, sweeping physical splits are nearly impossible. Encoding-layer upgrades plus compatibility piggybacking become the realistic path. When reader and writer both belong to one engine, the layout can evolve freely with version numbers and the design space opens up.
- Is the format a “general container” or an “OLAP segment”? A general columnar container (Parquet, Lance) carries needs from many upper-layer engines. Schema evolution, secondary indexes, and transactions get pushed up the stack on purpose. This kind of format has the motivation to keep its footer thin and regular. An OLAP engine’s own segment (Doris segment, ClickHouse part) treats schema evolution, indexes, MOW (Merge-on-Write), Cluster Key as first-class. Its footer carries that baggage, and evolution can only be minimally invasive surgery.
Parquet, Lance, and Doris segment sit at different positions across these two axes. Even when all three solve the same problem, the knob combinations end up looking nothing alike. With these constraints in mind, many “why didn’t they do it that way” questions about the three solutions ahead trace back to the constraints.
4. Parquet’s Solution: An In-Place Engine Swap Under Ecosystem Constraints
Parquet has the longest history and the largest ecosystem of the three. Its footer design has barely changed since 2013: described in Thrift, sitting at the file tail, requiring readers to consume the whole segment before doing anything. That stability is why Parquet became the de facto standard. It’s also why Parquet hit the metadata explosion wall first. As wide tables, AI datasets, and Variant fields spread, the pain on Parquet’s footer surfaced earlier than anywhere else.
In early 2025, Databricks engineers posted a “Flatbuffer footer” proposal to the Parquet mailing list, restructuring the footer in a fairly systematic way. Look first at where Parquet’s current footer is fat, then at what the proposal does.
4.1 Where Parquet’s current footer is fat
“The footer is big” surprises no one. The fat points the proposal pinpoints are more concrete than you might expect. Four stand out.
Statistics stores physical-type values as generic binary.
The min and max fields in Parquet’s column-level and page-level Statistics are typed binary and hold PLAIN-encoded physical values. For fixed-length types (int32, int64, float, timestamp, decimal), the binary wrapping is pure waste. Every min/max carries a length prefix, and on the C++ side it gets wrapped in std::string with allocation overhead included. On a wide table with thousands of columns, statistics alone can take the bulk of the footer.
path_in_schema is fully derivable.
Every column carries a path_in_schema: list<string> listing its full path through the nested schema (for example, ["user", "address", "city"]). But the schema sits in the footer too, and path_in_schema can be derived from a depth-first walk. Classic redundant field, stored to keep reader implementations simple. Historical burden.
OffsetIndex / ColumnIndex are O(C × R) hotspots.
OffsetIndex records each page’s row range and byte offset; ColumnIndex carries page-level min/max. They power page-level predicate pushdown, and they cost one independent structure per column per row group (O(C × R)), each starting at a few hundred bytes. On a large wide table with many row groups, these typically claim more than half the footer.
Thrift’s sequential decoding is fundamental.
Thrift Compact uses ULEB128 for tags and lengths. Every field decodes from start to end in order. Even when you only want row_groups[0].columns[42], the decoder still has to walk through 41 columns of metadata first. Field-level trimming alone can’t fix this.
These four together make Parquet’s current footer both heavy to read (IO) and slow to parse (CPU) on wide tables and many-row-group files.
4.2 What the proposal does
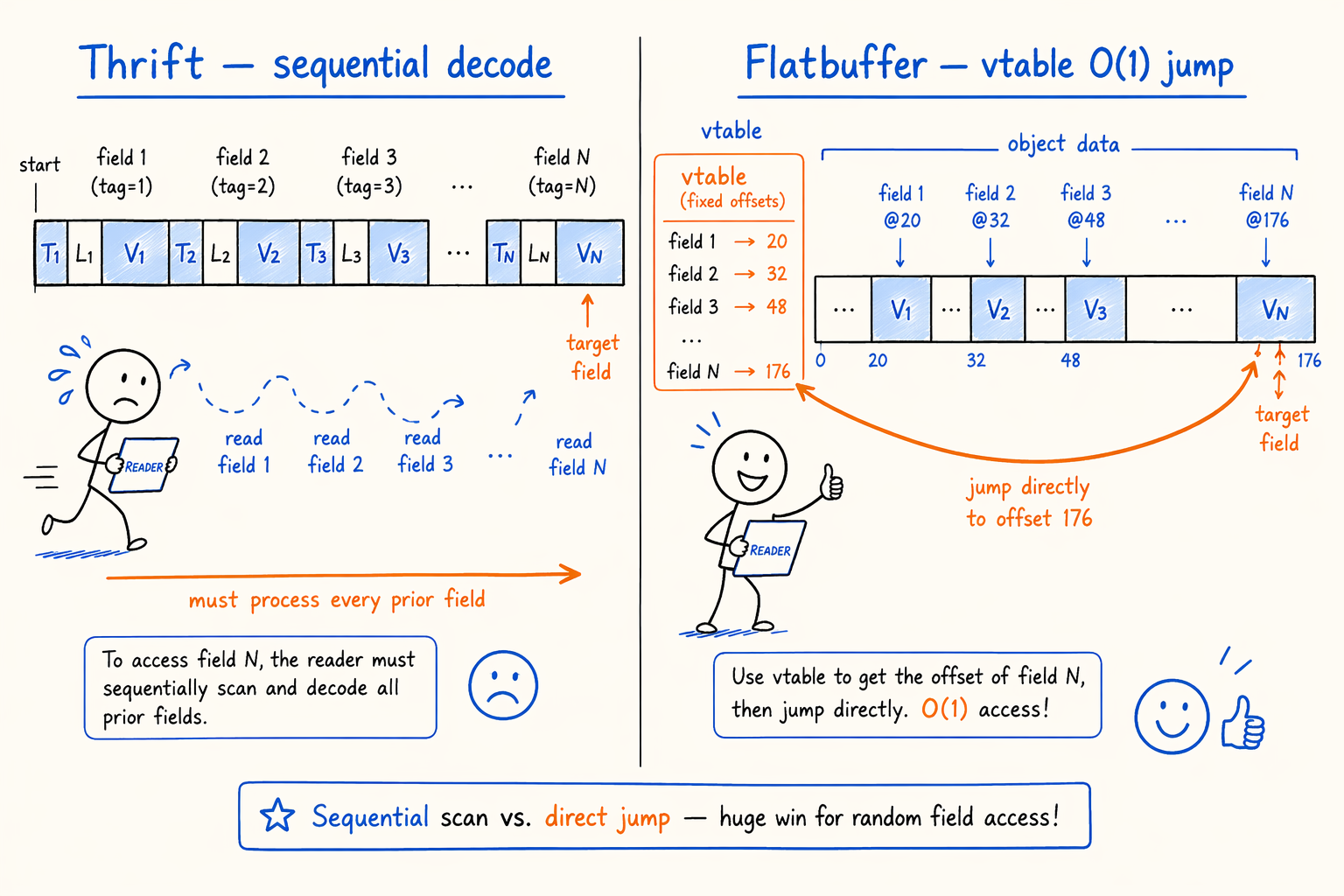 Figure 4.2 · Flatbuffer vtable random access vs Thrift sequential decoding.
Figure 4.2 · Flatbuffer vtable random access vs Thrift sequential decoding.
Mapped to the three knobs above, the proposal turns A, B, and C all at once.
(A) Switch the core footer to Flatbuffer. Flatbuffer is Google’s binary serialization format, designed for zero-copy reads with O(1) field access. Its vtable gives every field a fixed offset, so decoding is a pointer jump instead of a sequential walk. Even when the footer remains one segment that must be fetched whole, “give me column 42’s metadata” jumps straight there. CPU time drops from O(C × R) to O(C_r × R).
Cost: Flatbuffer uses fixed-length encoding and loses bytes against Thrift’s ULEB128. The proposal claws it back through a series of layout trims (see C below), staying flat or even smaller overall.
(C) Field-level trims.
- Typed Statistics. Pick fields by physical type. Int32/int64 use
min_lo4/min_lo8; decimal usesmin_lo8+min_hi8; string uses common prefix + 16-byte fixed suffix + length truncation (enough for min/max filtering, no need for the full value). This alone cuts statistics by more than half. - Drop redundant fields.
path_in_schema,file_path,file_offset,encoding_stats(degraded to a booleanis_fully_dict_encoded),ConvertedType, and others all go or simplify. - Cap row group size at 2³¹. Row count and byte count both stay under INT_MAX, so column chunk offset and size in a row group all shrink from int64 to int32. Saving 4 bytes per column per chunk, multiplied by C × R, adds up.
- Optional LZ4 compression on the whole footer. Flatbuffer’s vtables repeat heavily and entropy is low. LZ4 typically pays off.
(B) Move OffsetIndex / ColumnIndex out of the footer. These are the O(C × R) heavyweights. The proposal writes them into independent arrays outside the footer, and the footer keeps only an entry pointer. The footer body sheds a major burden, and page-level pruning fetches the relevant segment on demand. First large-scale appearance of the physical-split knob in Parquet.
4.3 The clever move: embedded extension compatibility
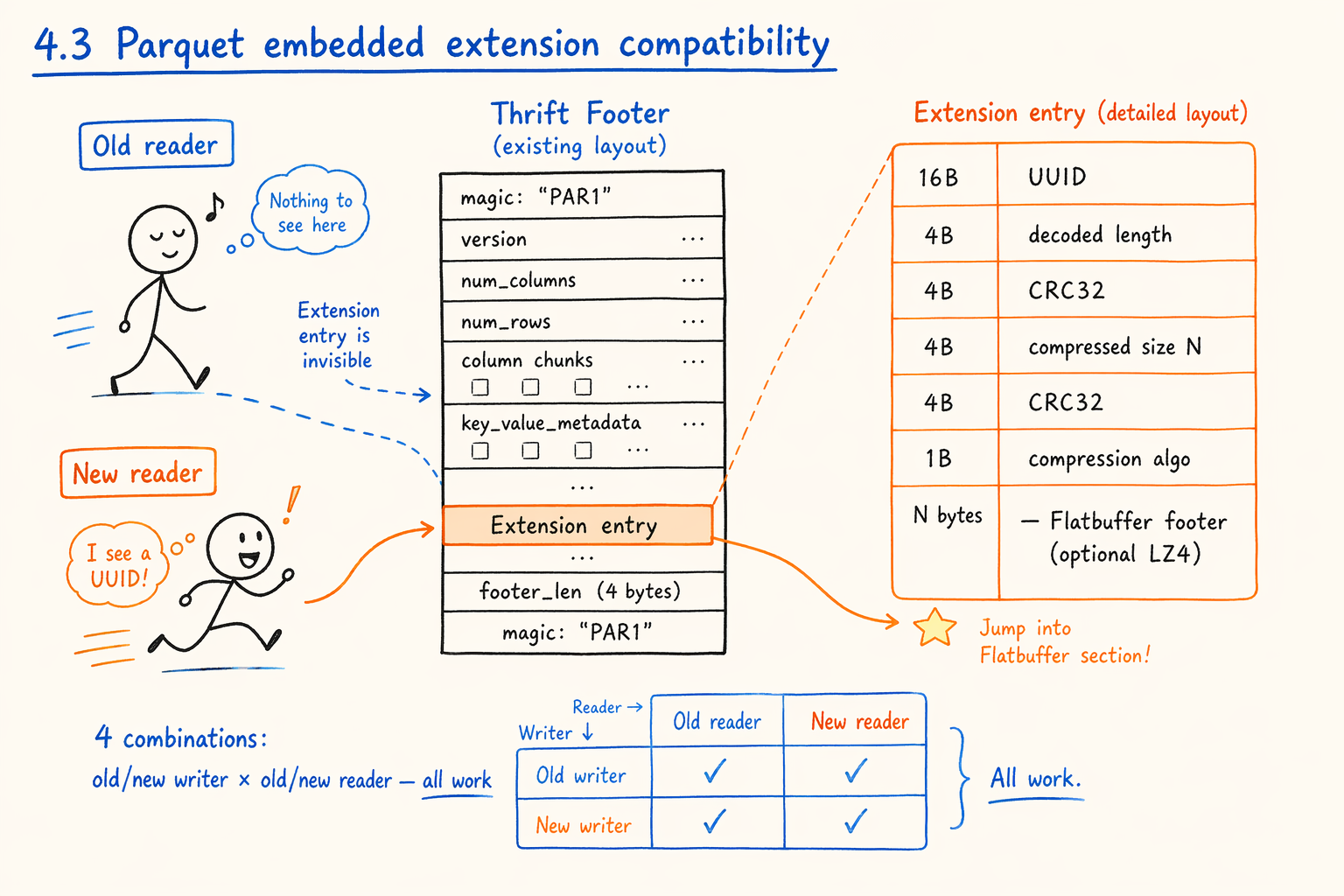 Figure 4.3 · The new Flatbuffer footer rides inside an extension slot in the old Thrift footer.
Figure 4.3 · The new Flatbuffer footer rides inside an extension slot in the old Thrift footer.
A, B, and C are technical detail. What actually makes the Parquet proposal interesting is how it lands these changes without breaking ecosystem-wide compatibility.
Parquet readers live in dozens of projects: Spark, Photon, Arrow, DuckDB, Impala, ClickHouse, Polars, Iceberg, Delta. Any change to the footer’s binary layout, in theory, requires every project to upgrade in lockstep. The proposal’s solution:
The new footer doesn’t replace the old footer. It rides inside an extension slot in the old Thrift footer.
Roughly:
1
2
3
4
5
6
7
8
9
10
[ ... old Thrift footer fields ... ]
[ extension entry:
16 bytes UUID ← marks this as the flatbuf footer extension
4 bytes uncompressed length
4 bytes crc32(first 8B)
4 bytes N (compressed bytes)
4 bytes crc32(first N+1B)
1 byte compression algorithm
N bytes flatbuf footer (optionally LZ4 compressed)
]
Old readers can’t see this segment. They recognize only the Thrift footer fields they know, and the extension slot gets ignored. New readers, when parsing the Thrift footer, see the UUID and jump to the flatbuf footer for O(1) field access.
The key property: all four combinations work (old writer + old reader, old writer + new reader, new writer + old reader, new writer + new reader). No project has to wait for another to upgrade its reader; no writer upgrade renders a file unreadable. This is the smartest piece of the proposal, and the precondition for the discussion. Without this compatibility layer, no technically beautiful proposal can move in the Parquet ecosystem.
4.4 Measured gains and lessons
The proposal cites a set of production numbers from inside Databricks:
- Decoding speed improves 1.5–3× for small and medium footers. Larger footers see bigger gains, since Flatbuffer’s field-level random access only shows its edge as footers grow.
- About 1‰ of footers in the old path exceed 256 KB and need at least two cloud fetches. With the new format, 95% of those resolve in a single fetch.
- These gains hold even with the intermediate “decode flatbuf, convert back to Thrift FileMetadata object” step still in place. If engines consume flatbuf directly without the round trip, an estimated 2× more is on the table.
Translated back into the knob framework, Parquet’s proposal has a clear signature:
- At the encoding layer (A), it makes the most decisive cut: Thrift to Flatbuffer. The biggest win compatibility allows.
- At field trimming (C), it does systematic, aggressive across-the-board pruning: typed statistics, redundancy removal, int32-ification. ROI is high here, and backward-compatibility pressure stays manageable.
- At physical splitting (B), it dips just one toe: move OffsetIndex / ColumnIndex out, but leave column meta in place. Touching the latter means a layout-level rewrite and ecosystem cost too high.
- The compatibility constraint (the first one in 3.2) forces all of the above to ship as embedded extensions. That’s the other half of the work, beyond the technical changes.
Parquet’s solution shows one thing clearly: when readers aren’t yours, the ceiling on footer optimization is largely set by what compatibility allows, not by what the design could be. Lance and Doris don’t face this constraint, and that’s the root reason they can take more aggressive paths.
5. Lance’s Solution: Redesigning a Thin Container for New Scenarios
Lance is an open-source columnar file format the LanceDB team has been building since 2022. Its positioning is clear: a columnar container for ML training data, vector retrieval, and multimodal datasets. It wasn’t built to replace Parquet. From the start, it accepts that it serves one specific scenario, and that lets it make container-level choices Parquet and OLAP segment formats can’t make under their historical baggage.
To understand Lance, start with two premises:
- Column counts in target scenarios run high. Thousands of columns per file is the norm (a 768-dimensional embedding becomes 768 columns, plus various features). But any single read picks only a few or a few dozen.
- No SQL-engine baggage. Schema evolution, secondary indexes, transactions, MOW aren’t problems Lance solves directly. They sink down to the upper layers (DataFrame, vector library, feature store).
These two drive Lance toward “thin container, fully independent columns.”
5.1 File skeleton
A Lance file’s core skeleton, bottom-up:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
┌─────────────────────────────────────────────┐
│ Data Buffers (multiple pages) │ ← actual column data; page is the IO unit
├─────────────────────────────────────────────┤
│ Per-column Metadata │ ← one independent protobuf per column
│ ColumnMetadata(col_0) │ describes that column's pages and encoding
│ ColumnMetadata(col_1) │
│ ... │
├─────────────────────────────────────────────┤
│ Column Metadata Offset Table │ ← (pos, size) array, one per column
├─────────────────────────────────────────────┤
│ Global Buffers Offset Table │ ← directory for global auxiliary metadata
├─────────────────────────────────────────────┤
│ Footer (fixed ~40 bytes) │
│ u64 offset to column_meta[0] │
│ u64 offset to CMO Table │
│ u64 offset to GBO Table │
│ u32 num_global_buffers │
│ u32 num_columns │
│ u16 major_version │
│ u16 minor_version │
│ "LANC" magic │
└─────────────────────────────────────────────┘
Three design choices in this skeleton are worth pulling out separately.
5.2 Footer fixed at ~40 bytes
Lance’s footer is a fixed-length binary structure: 3 u64 + 2 u32 + 2 u16 + 4-byte magic, about 40 bytes total. It has nothing to do with column count. Whether the file has 5 columns or 5000, the footer stays the same size.
So the first step of the read flow (“read the tail to get the footer”) collapses from a multi-step “probe length, then fetch” operation into a single “just read 4KB or 16KB at the tail as one sector.” The footer always sits in that sector, and the CMO Table usually rides along too.
Cost: the footer can hold almost no business fields. Schema, statistics, and index pointers all live elsewhere. Lance’s answer is Global Buffers, an independent byte region holding any key/value global data (the schema usually sits in global buffer 0). The footer refers to them through the GBO Table.
5.3 One independent protobuf per column
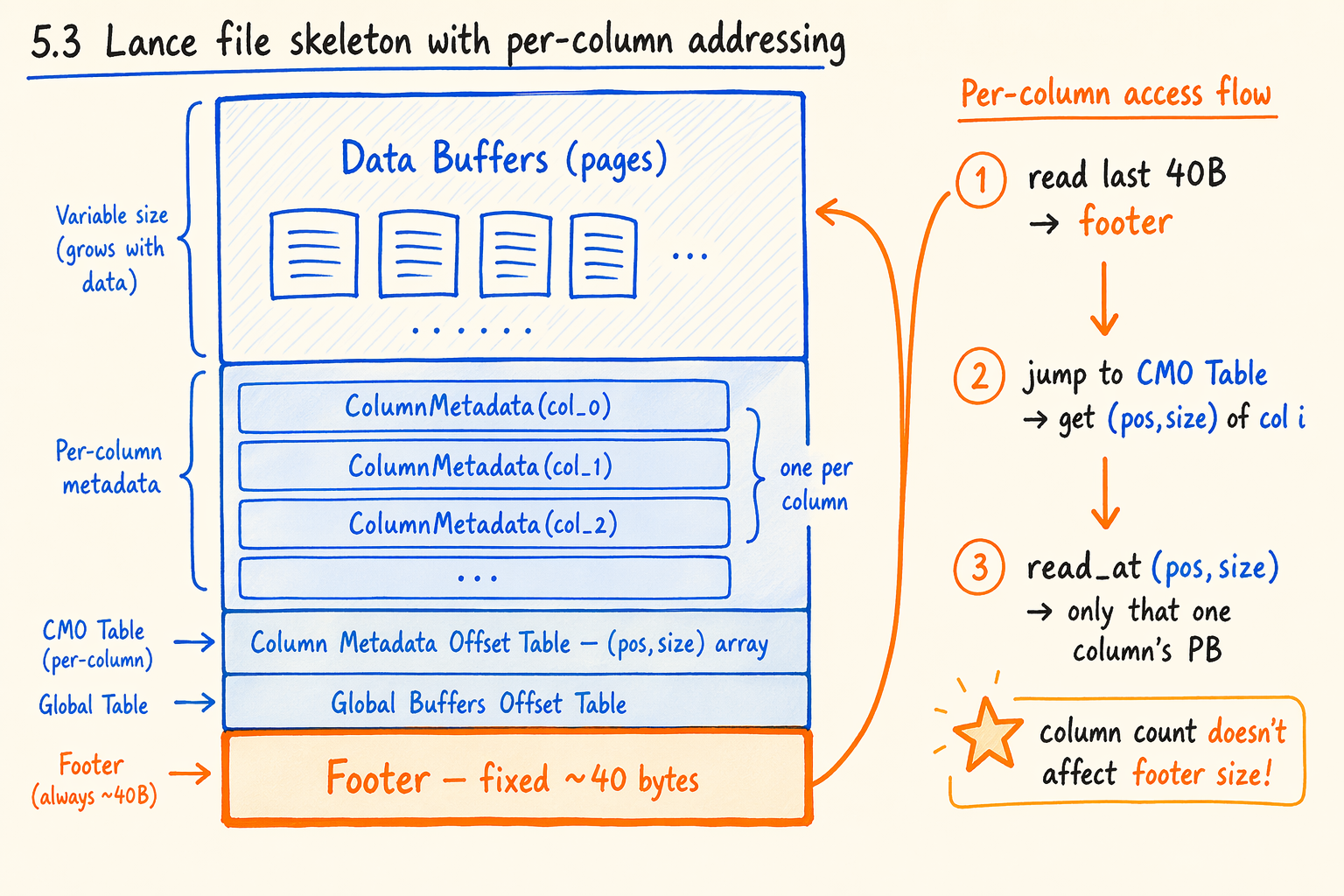 Figure 5.3 · Lance file skeleton: per-column protobuf with explicit (pos, size) addressing.
Figure 5.3 · Lance file skeleton: per-column protobuf with explicit (pos, size) addressing.
Lance’s column metadata isn’t packed into one continuous segment. Each column gets its own protobuf message (ColumnMetadata), plus an explicit Column Metadata Offset Table (CMO Table) holding (u64 pos, u64 size) × num_columns.
Locating column i’s metadata:
- Pull the CMO Table’s offset and
num_columnsfrom the footer. - Read the i-th entry to get
(pos, size). read_at(pos, size)fetches column i’s protobuf in one IO.- Parse that protobuf. Other columns’ metadata stays untouched.
Compared to Parquet’s “footer holds a nested array of row_groups[].columns[],” the difference is fundamental. Lance splits “column selection + meta read” at the IO layer. Parquet, even after Flatbuffer, still reads the whole footer first and then does field access.
5.4 No row groups
Parquet, ORC, and Doris segment all have a row group concept (or its equivalent): a file consists of multiple row groups, and each row group splits by column. Row groups exist to give a natural unit for parallelism and partitioning during concurrent reads and writes.
But row groups also act as a multiplicative factor on footer size. Each new row group adds one more “metadata copy per column per row group,” with complexity O(C × R). This is precisely where OffsetIndex / ColumnIndex grow worst in the Parquet proposal.
Lance picks no row groups at all. A file is a set of pages. Each page carries first_row_offset, and any read from an arbitrary row uses partial page reads. The R dimension drops out of the formula entirely. Footer size depends only on column count. Stack 5.2 and 5.3 on top, and the footer stops being the bottleneck for on-demand reads.
There are costs. Partial page reads need more careful reader implementation. Smaller pages raise the per-page metadata share; larger pages widen the partial read range. Lance defaults to ~8MB pages and supports External Buffers to push oversized cells (images, long vectors) out of line, preventing one giant cell from blowing up a page.
5.5 Lance on the three knobs
Mapped to the A/B/C framework:
- Encoding (A): fixed-length binary + explicit offsets. Even more thorough than the Parquet proposal’s Flatbuffer. Field access is constant time without a vtable.
- Physical splitting (B): the farthest of the three. Column metadata is fully per-column independent, the footer holds almost no business fields, and even the schema is externalized as a global buffer.
- Field trimming (C): not a focus, since a fixed-length tiny footer makes trimming irrelevant.
Lance gets there by accepting a set of constraints:
- Schema, secondary indexes, transactions, and row-level updates all live above the container, not inside it. Drop Lance straight into an OLAP segment slot and you’ll need to bolt on a layer for schema evolution, statistics, and indexes.
- The container layer doesn’t know types. Column numbers are just
[0, num_columns)indices. When the schema evolves and “add column / drop column” shifts indices, old files need an upper-layer mapping to read. - No native parent-child column concept. Semi-structured fields need flattening into regular columns at a higher layer.
These constraints barely apply to ML training data and vector dataset scenarios (no transactions needed, schemas are stable, fields are flat). Lance gets the full benefits of the thin container. Move it into an OLAP engine, though, and each constraint becomes a problem to solve. That’s why Doris segment didn’t follow Lance’s path and went the minimally invasive route below instead.
6. Doris Segment: The Minimally Invasive Surgery from V2 to V3
Doris is an OLAP engine, and segment is its columnar file format. It carries a full set of OLAP capabilities: MOW (Merge-on-Write) delete bitmap, Cluster Key, Primary Key, short key index, Bloom Filter, Inverted Index, ANN Index, Variant semi-structured fields. All of these live inside the segment itself, unlike Parquet, which leaves operator capabilities to the upper engine, and unlike Lance, which externalizes business fields entirely.
Section 2 covered segment v2’s pain. Every column’s ColumnMetaPB lives inline in the footer; Variant fields explode into many sub-columns and grow the footer to dozens of MB; querying a Variant sub-column means linearly scanning every sub-column’s metadata. The segment v3 Doris shipped in 4.1 targets exactly these two problems.
But unlike Lance’s redesign-from-scratch, v3’s design goal is minimal invasion: don’t disturb segment’s overall layout, don’t break compatibility with old v2 segments, and don’t affect the OLAP capabilities stacked on top. The cuts it makes:
6.1 Externalize ColumnMetaPB to the CMO region
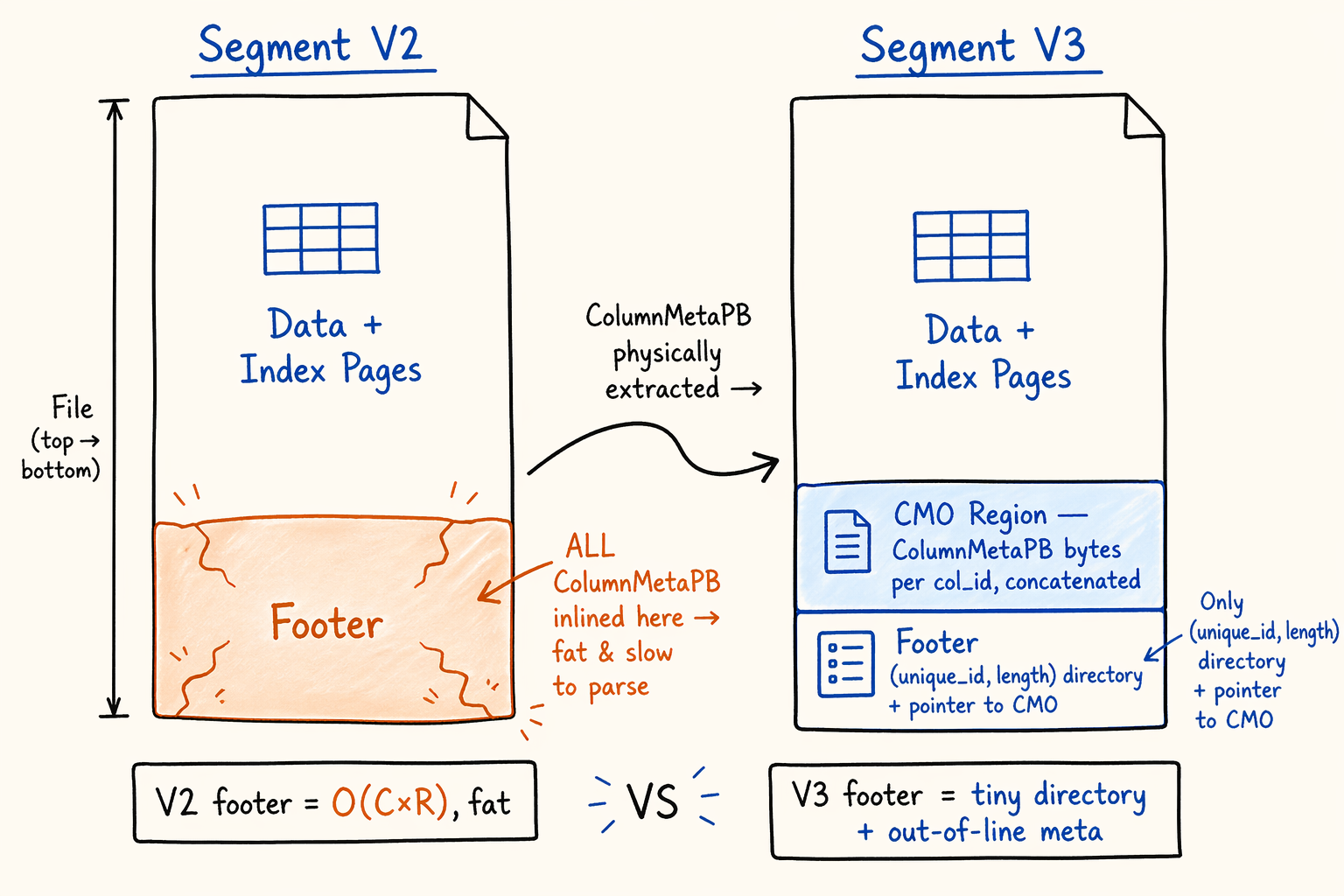 Figure 6.1 · Doris segment v2 vs v3 file layout: where ColumnMetaPB lives.
Figure 6.1 · Doris segment v2 vs v3 file layout: where ColumnMetaPB lives.
V3 adds a contiguous region before the footer, called the Column Meta Region (CMO). It concatenates the serialized bytes of every ColumnMetaPB previously inlined in footer.columns, sorted ascending by col_id. The footer’s repeated ColumnMetaPB columns field gets cleared, replaced by two new fields:
1
2
3
4
5
6
7
8
9
10
11
12
message SegmentFooterPB {
optional uint32 version = 1; // V2 = 1, V3 = 2
repeated ColumnMetaPB columns = 2; // empty in V3
// ... existing fields preserved
optional uint64 col_meta_region_start = 11; // V3 new: CMO starting offset
repeated ColumnMetaEntryPB column_meta_entries = 12; // V3 new: per-column directory
}
message ColumnMetaEntryPB {
optional int32 unique_id = 1; // top-level column unique_id; -1 for Variant sub-columns
optional uint32 length = 2; // bytes for this column's ColumnMetaPB in CMO
}
The file-level physical layout becomes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
┌──────────────────────────────────┐
│ Data + Index Pages │ ← unchanged
├──────────────────────────────────┤
│ Column Meta Region (CMO) │ ← V3 new: all columns' ColumnMetaPB concatenated
│ ColumnMetaPB(col_id=0) bytes │
│ ColumnMetaPB(col_id=1) bytes │
│ ... │
├──────────────────────────────────┤
│ SegmentFooterPB (serialized PB) │
│ columns = [] // cleared │
│ col_meta_region_start = ... │
│ column_meta_entries = [...] │
│ version = V3 │
├──────────────────────────────────┤
│ uint32 footer size + crc32 │
│ "D0R1" magic │
└──────────────────────────────────┘
To access column i’s metadata, the reader pulls column_meta_entries from the footer, runs an in-memory prefix sum to compute the column’s offset in the CMO region, then runs read_at(col_meta_region_start + offset, length) to fetch that segment in one IO, and finally ParseFromArray produces the ColumnMetaPB. This path goes through Doris’s INDEX cache lane, and repeat accesses get absorbed by cache.
The contrast with Lance is interesting:
- Lance picks per-column independent protobufs + an explicit (pos, size) table. Every column is fully independent, locating one takes one IO.
- Doris v3 picks CMO region concatenation + a (unique_id, length) array inside the footer. Locating one column is also one IO (the prefix sum runs in memory), but the footer is still a variable-length protobuf. At extreme column counts the entries array nudges the footer up by a few bytes per column.
Why doesn’t Doris just make the footer fixed-length like Lance? It can’t. The footer still has to carry short key index, cluster key, primary key, and various V2-era fields. Those can’t be dumped just for “a fixed footer.” Under “must keep the protobuf footer,” externalizing CMO and putting a directory inside the footer is the highest-ROI choice.
One more detail. Doris uses unique_id as the stable column identifier, not the column index Lance uses. unique_id is the never-reused ID TabletSchema assigns to each column, and it stays the same through column additions and removals. This matters in OLAP. A table that’s been running for three years, added 50 columns, dropped 30, still maps old segments correctly under the new schema, because the CMO region addresses by unique_id. Use a column index instead and the old files become unreadable immediately.
6.2 Variant sub-column two-layer folding and the path secondary index
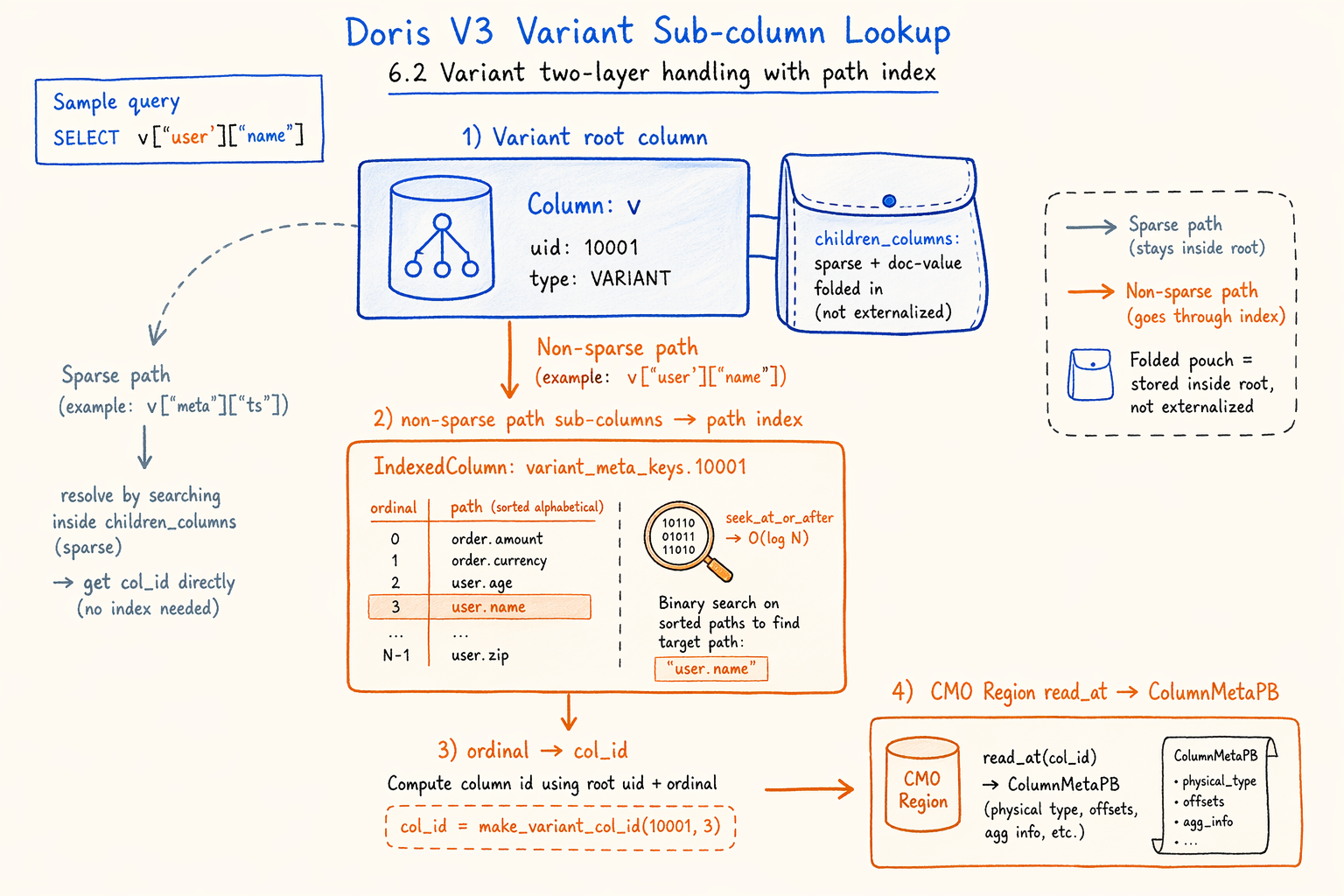 Figure 6.2 · Two-stage lookup: Variant path → ordinal → out-of-line ColumnMetaPB.
Figure 6.2 · Two-stage lookup: Variant path → ordinal → out-of-line ColumnMetaPB.
Lifting ColumnMetaPB out of the footer covers normal wide tables. For Variant semi-structured fields, a harder problem remains: there are many sub-columns, and queries usually project only a few paths.
V3 handles Variant in two layers.
Layer 1: fold sparse and doc-value sub-columns back into the root.
A meaningful fraction of Variant sub-columns are sparse sub-columns (split by bucket for sparse paths) and doc-value sub-columns (used for full-text search). They almost always read alongside the root, and rarely get hit by a single query alone. V3 embeds them directly into the root column’s ColumnMetaPB.children_columns field as part of the root, and they don’t enter the CMO region for independent addressing. When the root’s metadata gets read, sparse and doc-value information come along, avoiding a per-bucket lookup for each sparse bucket.
Layer 2: non-sparse sub-columns go through a path secondary index.
The sub-columns that might actually be projected independently are regular path sub-columns (like variant['user']['name'], variant['order']['amount']). For each Variant root, V3 writes an independent IndexedColumn (a VARCHAR column with value index, sorted lexicographically) keyed variant_meta_keys.<root_uid>, holding the sorted path strings of every non-sparse sub-column.
This IndexedColumn sits in the footer’s file_meta_datas, a generic key/value channel, and the footer holds only its IndexedColumnMetaPB (which points to the actual index pages).
With this layer in place, the read path for a Variant sub-column becomes:
- Get the root’s
ColumnMetaPBvia the 6.1 CMO path. - Find the
variant_meta_keys.<root_uid>IndexedColumn and load its reader. - Run
seek_at_or_after(rel_path)for a lower_bound lookup on this IndexedColumn (O(log N)). - Compute the sub-column’s
col_id = root_col_id + 1 + key_ordinal. The write side ensures sub-columns sit right after the root in the CMO region, sorted lexicographically by path. - Take the 6.1 path again by col_id to fetch the sub-column’s
ColumnMetaPBand build the sub-column reader.
The same index gives has_prefix(prefix) for free, implemented with the same lower_bound, answering “does this segment contain any path with this prefix?” in O(log N). Useful for dynamic projection and sparse path probing.
This layer is missing in both Lance and Parquet. Why: Lance’s container layer has no parent-child column concept, so semi-structured fields need upper-layer flattening. Parquet’s Variant LogicalType only landed in 2024 and still lacks path-level metadata indexing. Because semi-structured is a default-on capability in Doris, Doris has to do this layer inside the segment.
6.3 Lazy loading by unique_id and LRU caching
The CMO path is on-demand, but on-demand also means each first access pays one extra IO. V3 stacks two layers of buffering on the reader side:
ColumnReaderCache: an LRU keyed by unique_id, caching constructedColumnReaderobjects. Hit rate is very high when the same segment is accessed repeatedly.load_all_once(combined withDorisCallOnce): Variant sub-column tree loading uses once semantics, so concurrent multi-thread access triggers one lookup + parse, with other threads waiting on a read lock.
Combine this with the first read going through the INDEX cache lane (hitting the BE’s internal page cache), and the “extra IO” CMO introduces gets amortized to nearly zero in production.
6.4 V3 on the three knobs
Back to the A/B/C framework:
- Physical splitting (B): goes fairly far, but a notch more conservative than Lance. The CMO region concatenates rather than uses per-column independent protobufs, and the footer remains protobuf. The compromise paid to leave segment’s existing layout intact.
- Encoding (A): almost no change. The footer stays protobuf and decodes sequentially. The reason differs from Parquet’s: Parquet didn’t change because it would impact the ecosystem; Doris didn’t change because the footer is already small and the ROI on switching encoding is low.
- Field trimming (C): also barely moves. Statistics and various page metadata keep their V2 format.
- Variant path index: a specialized treatment Lance and Parquet both lack. Scenario-driven, since semi-structured is a default capability in Doris and there’s no skipping it.
V3 in one sentence: while preserving every OLAP-segment capability, externalize the two real bottlenecks (column metadata and Variant sub-column lookup) and add a secondary index, and leave everything else alone. The typical solution under the controlled-readers + OLAP-segment-format constraint pair.
The cost is clear too. V3 still carries the row-group + variable-length-footer historical baggage. The footer still grows linearly with column count (a few bytes per column, but still), and whole-footer reads with sequential decoding still happen. If Doris wants to keep moving toward Lance’s direction, possible next steps include making column_meta_entries a truly independent Offset Table to push the footer toward fixed length, or giving Statistics the typed trimming the Parquet proposal does. Both are diminishing-return optimizations, and whether and when to do them depends on how the workload evolves.
7. Putting All Five into One Coordinate System
Sections 4 through 6 covered Parquet’s current format, the Parquet new proposal, Lance, Doris segment v2, and v3 separately. This section puts them back into one coordinate system. Three concrete query scenarios show how each format handles “the cost of reading N columns,” followed by a tight matrix that summarizes the most important dimensions.
7.1 Scenario A: a 3000-column wide table, SQL reads 2 columns
Common in CDP and risk-feature warehouses. A single table with thousands of columns, where most queries touch only two or three.
- Parquet current: the footer is a single Thrift segment that must be pulled back in full from object storage and decoded sequentially through
row_groups[].columns[]to find target columns. When the footer is in MB, two fetches usually run, and deserialization time often sits in the same order of magnitude as the column data IO itself. - Parquet proposal: the footer is still one segment, but OffsetIndex / ColumnIndex move out of it, Statistics and redundant fields trim down, and Flatbuffer plus optional LZ4 land on top. In the proposal’s data, 95% of footers over 256 KB drop from two fetches to one, and field access inside the footer becomes O(1). The whole footer still reads in first, though.
- Lance: the fixed ~40-byte tail directly gives the Column Meta Offset Table’s location. Reading two columns means
read_at(pos, size)for those two columns’ protobufs only. Footer size is independent of column count. Metadata IO is nearly identical for 2 columns and 3000 columns. - Doris segment v2: every
ColumnMetaPBlives inline in the footer. Expanded across 3000 columns, the footer can reach several MB. Pulling two columns requires deserializing the entire footer, and CPU cost scales linearly with column count. - Doris segment v3: only the
(unique_id, length)directory remains in the footer. After computing the target column’s CMO position with a prefix sum, tworead_atcalls fetch the columns. Footer size returns to the KB range, and read cost lands on two column-level range reads.
The gap between Lance and Doris v3 here sits at “is the footer fully constant?” Doris’s footer still carries an O(C) directory, but it’s gone from “must parse all column meta” to “just compute an offset.” The Parquet proposal’s goal is more restrained: make field access cheap once one fetch returns the whole footer.
7.2 A measurement: V2 vs V3 on extremely wide tables
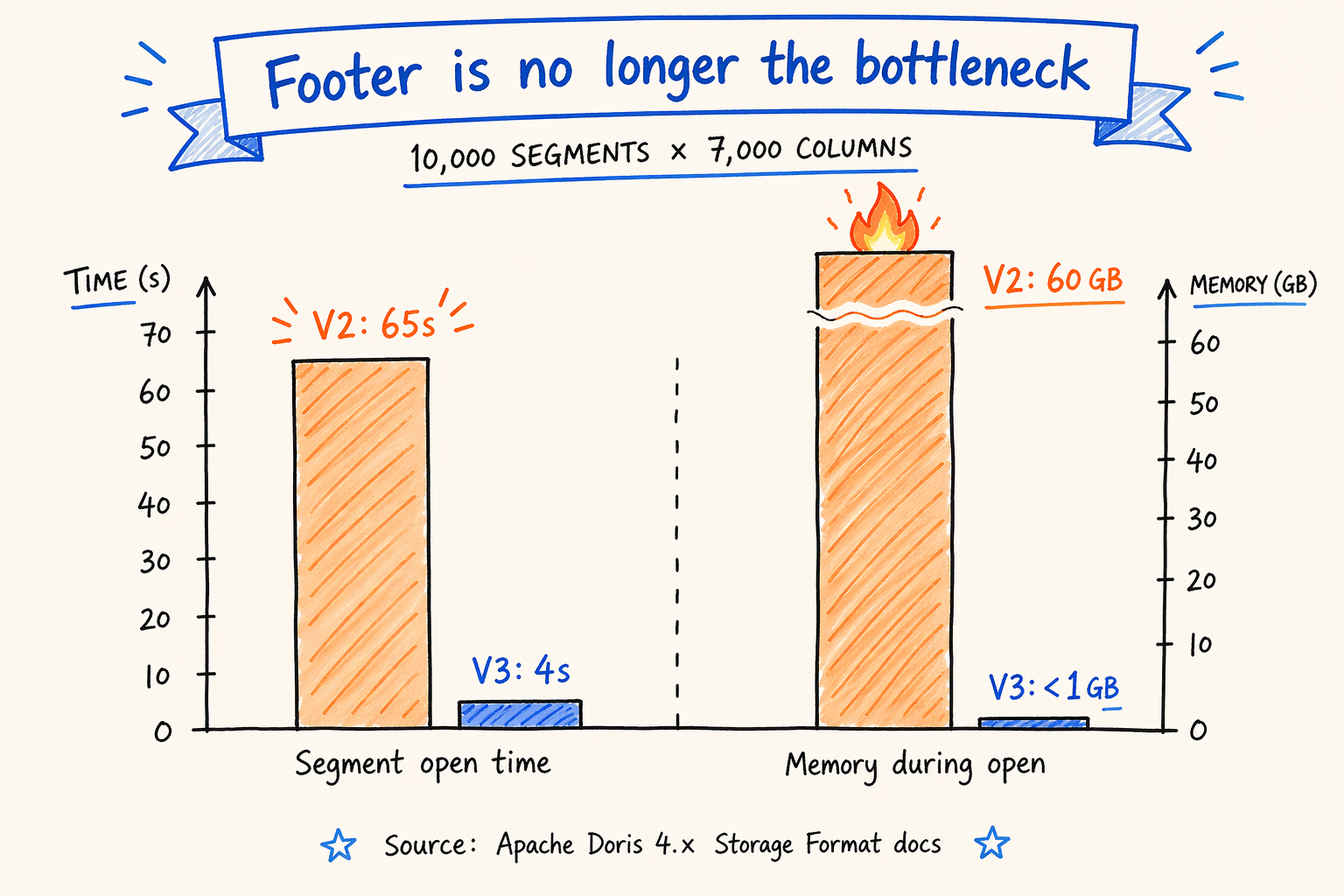 Figure 7.2 · Segment open time and memory: v2 vs v3 on 7000-column wide segments.
Figure 7.2 · Segment open time and memory: v2 vs v3 on 7000-column wide segments.
Apache Doris 4.x official documentation gives a set of numbers on extreme wide tables: 10,000 segments with 7,000 columns each. Looking at segment open cost only:
| Metric | V2 | V3 |
|---|---|---|
| Segment open time | 65 s | 4 s |
| Memory during open | 60 GB | < 1 GB |
Source: Apache Doris 4.x Documentation / Storage Format.
The cause matches scenario A’s qualitative analysis. V2 has to deserialize the entire footer (with every column’s ColumnMetaPB) before serving queries; more columns means a bigger footer and a higher memory peak. V3 reads a thin footer for the directory, then fetches metadata only for columns the query actually touches. Most columns never enter the end-to-end flow.
A caveat. V3 in the BE layer also flips the default for integer column plain encoding and BINARY_PLAIN_ENCODING_V2. These two settings mostly affect the column data decoding path, not footer parsing, but they still contribute extra differences in an end-to-end benchmark. To isolate the footer’s contribution, the test needs explicit control over these encoding switches. The reasonable read of this number is “V3 makes the footer no longer a bottleneck during segment open on extreme wide tables,” not “every difference traces to the footer alone.”
Another sense check. The workload above is “open metadata for 10,000 segments,” which maximizes the impact of footer optimization. On a regular table with fewer than a few hundred columns and no Variant, the gap between V2 and V3 shrinks substantially. Which is why the official documentation explicitly recommends keeping V2 for narrow tables.
7.3 Scenario B: a Variant column with 1000 sub-paths, query projects v['a']['b']
Common in semi-structured logs, user events, and IoT telemetry. A JSON field expands into thousands of sub-columns at write time.
- Parquet current / proposal: Variant in Parquet is currently just a LogicalType, and sub-paths still expand by column. Projecting one path requires the reader to understand the schema first to know which column maps to
v.a.b. Even with path pruning, schema parsing and the in-footer column walk in front are still O(total sub-columns). The proposal doesn’t add a path index for semi-structured data. - Lance: the container layer doesn’t distinguish parent and child columns, and semi-structured data has to be flattened to regular columns above (at the writer or table-format layer). Once flattened, 1000 sub-paths are 1000 columns, and reading a subset costs the same as scenario A. The flatten + maintain schema burden moves up the stack.
- Doris segment v2: Variant sub-columns expand and inline into the footer. Querying
v['a']['b']requires a linear scan over every sub-column’s meta. More sub-columns means a bigger footer and a slower projection. - Doris segment v3: sparse sub-columns fold back into the root’s
children_columnsinstead of externalizing. Non-sparse sub-columns live independently in the CMO region, with avariant_meta_keys.<root_uid>IndexedColumn providing a path → ordinal secondary index. Projectingv['a']['b']runs one O(log N) lookup for the ordinal, then fetches that one meta from the CMO region.has_prefixworks natively without an extra index in the reader layer.
This is where Doris v3 goes the farthest in the three-way comparison. It doesn’t just move meta out of the footer; it builds a separate index for semi-structured data. The cost is one more IndexedColumn type to maintain inside the segment and one extra path materialization step on the write path.
7.4 Scenario C: a table running for three years with dozens of column add/drop cycles
Common for long-lived business tables. Column renames, drops, additions, re-additions of the same name.
- Parquet family: a column’s primary key is its schema position, and column semantic stability depends on the external table format (Iceberg / Delta field ID mapping). The file itself can carry renames, but mapping column indices and type evolution between files written at different times depends on the table format layer.
- Lance: columns are identified by 0..N column indices. The simplest locator. Schema evolution similarly depends on an external table format or writer protocol to maintain “which index maps to which business field.”
- Doris v2 / v3: columns are keyed by
unique_id. No matter how many add/drop/rename cycles the schema goes through, the same business field always carries the same uid. Dropped columns leave tombstones; new columns get new uids; reusing a name causes no confusion. The CMO directory, the ColumnReaderCache key, and the Variant path index namespace all hang directly off uid.
This comparison isn’t about “who’s faster.” It’s about “who keeps a stable column identity inside the file itself.” Doris’s choice puts schema evolution complexity inside the segment. Parquet and Lance push it down to the upper table format layer. Both choices have their reasoning.
7.5 Compact comparison matrix
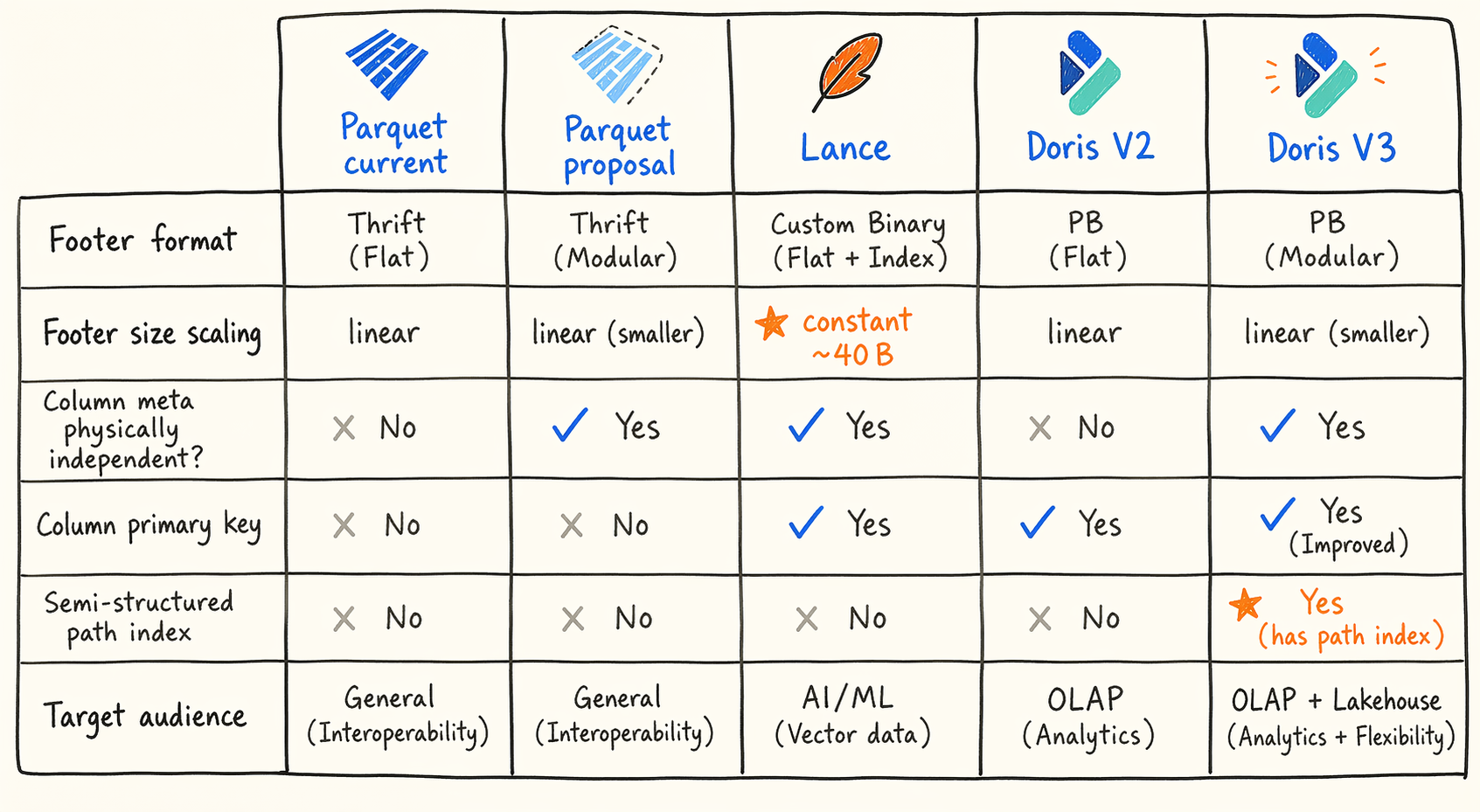 Figure 7.5 · Five formats, five trade-offs: where column metadata lives.
Figure 7.5 · Five formats, five trade-offs: where column metadata lives.
The table picks only the dimensions most directly tied to “metadata read on demand.” A fuller version sits in the original analysis materials; this one is deliberately trimmed.
| Dimension | Parquet current | Parquet proposal | Lance | Doris v2 | Doris v3 |
|---|---|---|---|---|---|
| Footer serialization | Thrift Compact | Thrift + embedded Flatbuffer | Fixed binary + per-column PB | Protobuf | Protobuf |
| Footer size profile | O(C × R) | O(C × R) but heavily trimmed | Constant ~40 bytes | O(C × R), grows when sub-columns expand | O(C) directory |
| Column meta physically independent | No | No | Yes (per-column PB) | No | Yes (CMO region) |
| Column primary key | schema position | schema position | column index 0..N | unique_id | unique_id |
| Semi-structured path index | None | None | None (upper-layer flatten) | None | Yes (variant_meta_keys) |
| Compatibility strategy | Single-format incremental evolution | Embedded UUID, transparent to old readers | Major/minor pair | N/A | Footer version enum + V2 fallback |
| Target audience | Open ecosystem | Open ecosystem | ML / multimodal / vector | Doris itself | Doris itself |
A few key asymmetries. Lance’s footer is truly constant, at the cost of externalizing schema, indexes, and transactions. Doris v3’s footer is an O(C) directory rather than constant, trading the difference for putting the semi-structured path index inside the segment. The Parquet proposal is the only one that can’t change the layout, so all its moves crowd into the encoding and field layers.
8. “Best Solutions” in Different Coordinate Systems
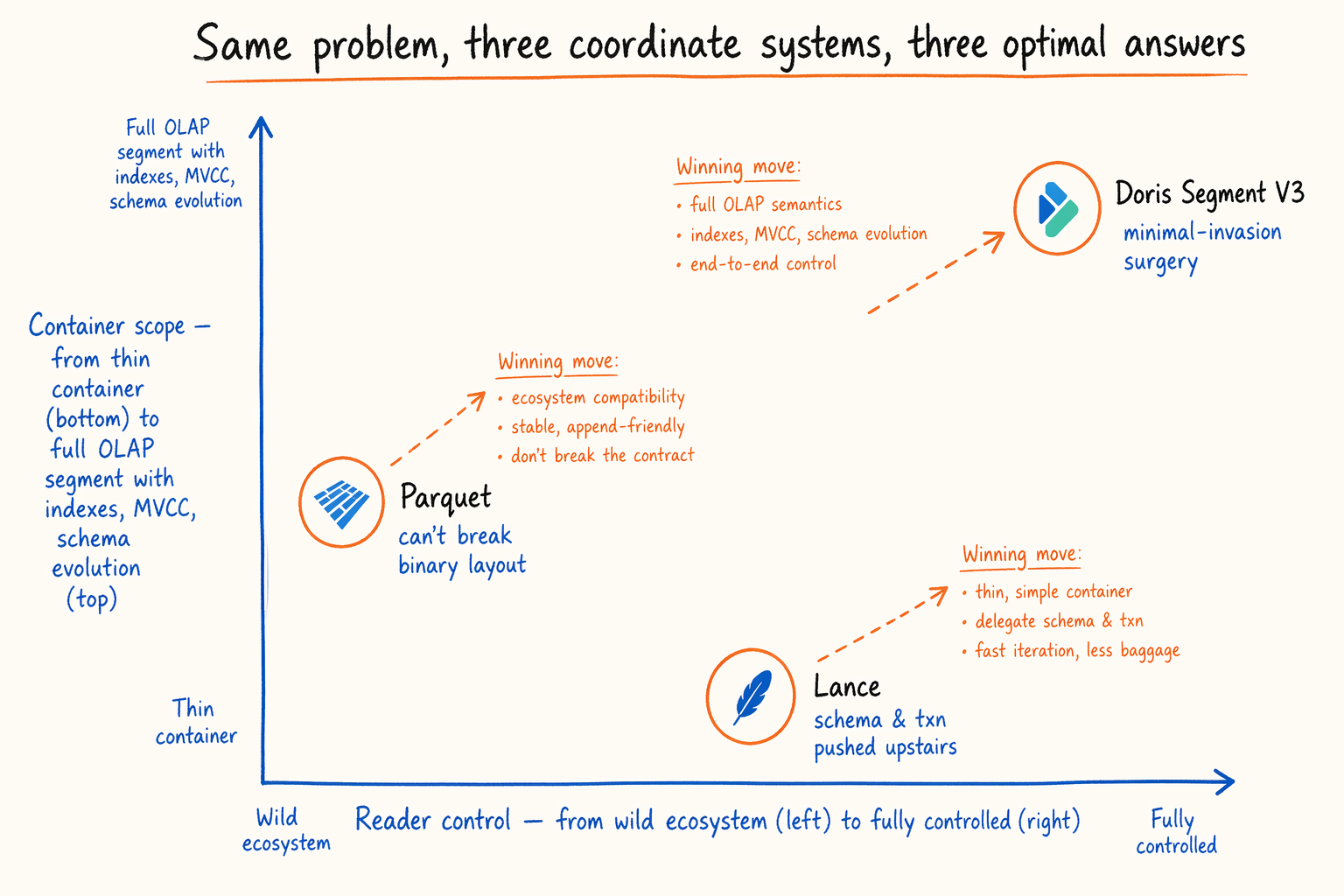 Figure 8 · Three formats placed on a two-dimensional coordinate system of constraints.
Figure 8 · Three formats placed on a two-dimensional coordinate system of constraints.
Looking at all three together, what’s clearer isn’t whose footer is smallest. It’s that every format made the best move it could under its own constraints. This section lays the constraints bare so the comparison settles at the design-philosophy layer.
8.1 A one-line positioning of each
- Parquet: ecosystem constraint is the first citizen. Any change that breaks the binary layout means dozens of reader implementations have to upgrade in lockstep, which is engineering-impossible. So the proposal picks “in-place engine swap”: carry a Flatbuffer mirror inside the Thrift footer, leave old readers oblivious, give new readers field-level O(1) access, then layer typed Statistics, field trimming, and OffsetIndex externalization on top.
- Lance: serves new scenarios like ML training, multimodal datasets, vector retrieval. These have no heavy historical reader base, and schema, indexes, and transactions are already managed in higher protocols. The container layer can stay extremely thin: 40-byte fixed footer, one protobuf per column, even row groups disappear. Lance hands off everything an upper layer can solve, in exchange for the cleanest possible “read on demand” at the container layer.
- Doris segment v3: operates within the OLAP engine’s own closed loop, but has to preserve MOW, Cluster Key, Primary Key, short key index, secondary indexes,
unique_id-driven schema evolution, semi-structured-by-default, and the rest of the existing capabilities. So it can’t tear down like Lance, and it doesn’t face Parquet’s “the whole ecosystem can’t upgrade” external constraint. The final choice is minimally invasive: externalize ColumnMetaPB to a CMO region, build a separate path index for Variant, and leave everything else as-is.
8.2 The same restraint: v2→v3 and current→proposal
Pull back further and Parquet’s current → proposal and Doris’s v2 → v3 share an engineering style: restrained evolution within the existing format’s boundaries, not a new format. Both insist on backward compatibility, neither plans to clean up historical baggage, and both cut only at the most painful spots. The difference is in constraint strength. Parquet’s compatibility pressure comes from the external ecosystem and even forbids changing the footer layout. Doris’s comes from its own existing clusters, so it can change the footer but must keep a V2 fallback path.
Lance sits on a different axis. It has no previous-generation format to maintain compatibility with, so it can design from scratch around “read on demand.” But that freedom carries a price. Schema evolution, indexes, and transactions must be caught by an upper-layer protocol, and a Lance file alone is incomplete.
8.3 A neutral conclusion
Put together, the three aren’t three implementations of one goal. They’re the best solutions to one problem in three different coordinate systems. Saying any of them is “more advanced” or “more outdated” misses the point. Outside the prerequisites of “are the readers yours?” and “is there a schema and index layer beyond the format?”, comparison stays at the surface-parameter level. The closer reading: under your coordinate system, which set of trade-offs pays best?
9. What They Can Borrow from Each Other
Each format still has room to learn from the other two. Engineering moves that could land, without expanding into a new round of design:
- Doris from Parquet: Statistics in zone maps still uses binary strings. Integer, decimal, and time types could adopt the proposal’s
lo4 / lo8 / hi8typed fields. Strings could adopt the common-prefix + 16-byte fixed suffix scheme. The space saved on wide tables would be meaningful. - Doris from Lance: extract
column_meta_entriesinto an independent Offset Table, leaving only an entry pointer in the footer. This pushes the footer closer to fixed length and lifts performance another step on extremely wide tables. - Parquet from Doris and Lance: physical splitting. The proposal’s move of OffsetIndex / ColumnIndex out of the footer is the first step on this path. One more step lands on something close to Doris’s CMO region.
- Lance from Doris: a path secondary index for semi-structured data. Today Lance relies on upper-layer flattening. If Lance ends up carrying more native semi-structured workloads, a capability like
variant_meta_keyswould have value.
Lay all these moves together and a shared direction emerges: the next round of columnar format evolution has shifted focus from “store data more tightly” to “let metadata be read on demand.”
Try Segment V3
Segment v3 ships with Apache Doris 4.1 and is the default format for new tables. If the scenarios in this post — wide CDP tables, Variant-heavy event logs, ML feature stores — match your workload, the fastest way to feel the difference is to open a v2 segment and a v3 segment side by side on a 3000-column table and watch the startup latency collapse.
- Read the format spec: Apache Doris 4.x · Storage Format — the CMO region layout, Variant path index, and V2 fallback knobs are all documented here.
- Download Doris 4.1: doris.apache.org/download — pick the 4.1 release; v3 is on by default for new tables, and v2 stays available for narrow-table workloads via
storage_format. - Questions or feedback: the Apache Doris Slack and GitHub Discussions are where the people who built segment v3 hang out. If you hit a footer-size edge case we haven’t seen, we want to hear about it.