Integrating Lance into Doris: Notes from the Rust Side
How Apache Doris embeds a Rust-based Lance reader in its C++ BE via the Arrow C Data Interface, a single-threaded Tokio runtime, and Corrosion.
Preface
Thanks to Tom for the contribution.
Apache Doris landed native Lance format support in PR #62182. The integration puts a block of Rust code inside Doris’s C++ process.
That’s more than “one more supported file format.” Once a working Rust component runs inside the BE, the next one costs much less to add.
This post covers four things: why Rust, why Lance, how a C++ process integrates with Rust, and what’s still left to do.
TL;DR
- Apache Doris PR #62182 lands a native Lance reader written in Rust, called from the C++ BE.
- Data crosses the FFI boundary via the Arrow C Data Interface — zero-copy
RecordBatchpassing, no hand-written marshaling on either side. - A single-threaded Tokio runtime plus
block_onkeeps Lance’s async IO contained on BE’s own worker thread. Concurrency moves up to fragment-level scan ranges instead. - Corrosion wires Cargo into CMake so the Rust toolchain stays a one-file integration in
rust.cmake. - Binary cost:
libdoris_native.ais ~430MB; the final BE grows 50–80MB after LTO. A one-time infrastructure cost the next Rust components (delta-rs, iceberg-rust, OpenDAL) amortize. - Shipping today: projections,
WHERE,LIMIT, aggregations onlocal()/s3()TVFs. Still open: a Lance Catalog, filter and vector pushdown, andBlockFileCacheintegration.
1. Rust in data infrastructure
A lot of the data-infra projects that showed up in the last few years are written in Rust:
- Query engines and databases: DataFusion, Polars, RisingWave, Databend, GreptimeDB
- Storage and lake formats: Lance, delta-rs, iceberg-rust, Apache OpenDAL
- Systems infrastructure: TiKV, Vector, Tokio, Deno, Turbopack
- AI infrastructure: Hugging Face Candle, Burn, Rust bindings for
llama.cpp
The reasons are well understood at this point: no GC and C++-level throughput, an ownership model that rules out a lot of memory-safety and data-race bugs before they ship, and Cargo, which makes it cheap to start a project and pull in dependencies.
What matters for us is the second-order effect. A bunch of high-quality data components now live in the Rust ecosystem, and for a C++ engine like Doris, integrating one of them tends to be cheaper than rewriting it. Doris BE is C++ and Doris FE is Java; this post is about how we make room for Rust code inside the C++ process.
2. Lance: a columnar format built for multimodal data
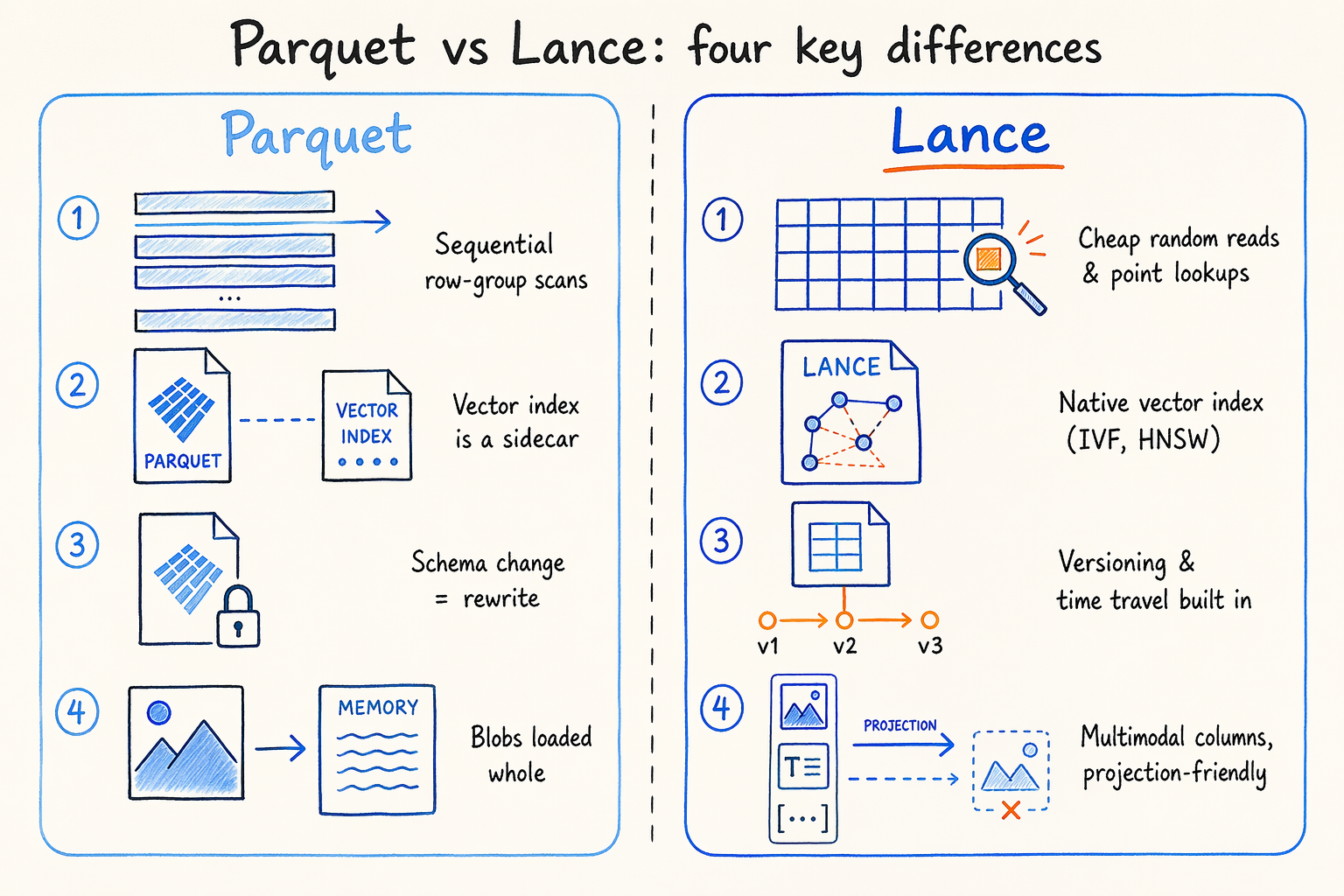
Lance is a columnar format from the LanceDB team, positioned as “AI native.” Four things separate it from Parquet:
- Random reads are cheap. Parquet assumes you’re sequentially scanning complete row groups; Lance is tuned for point lookups and small-range scans, which is closer to how AI inference, vector recall, and tag filtering actually read data.
- Vector indexes (IVF, HNSW, and others) are part of the format, not a sidecar. You don’t need a separate vector index alongside a Parquet table.
- Dataset versioning and time travel are built in. Schema evolution (adding columns, changing types) doesn’t require a data rewrite.
- Multimodal fields — images, embeddings, long documents — sit naturally in Lance’s columnar layout, and projection queries skip loading the blob into memory.
Lance isn’t Parquet with AI features bolted on — it was designed for AI workloads from the start.
3. Doris + Lance: what each side brings
Doris started out as a structured OLAP engine and picked up multimodal features along the way.
3.1 What Doris already does for multimodal workloads
Doris provides:
- A structured analytics foundation: MPP vectorized execution, materialized views, and a cost-based optimizer.
- Native ANN vector indexes (HNSW-based) for vector similarity recall directly in SQL.
- Built-in inverted indexes with BM25, phrase matching, and fuzzy matching. No Elasticsearch required.
- The
VARIANTtype for dynamic JSON and schemaless data, so text, tags, and embeddings can coexist in one table.
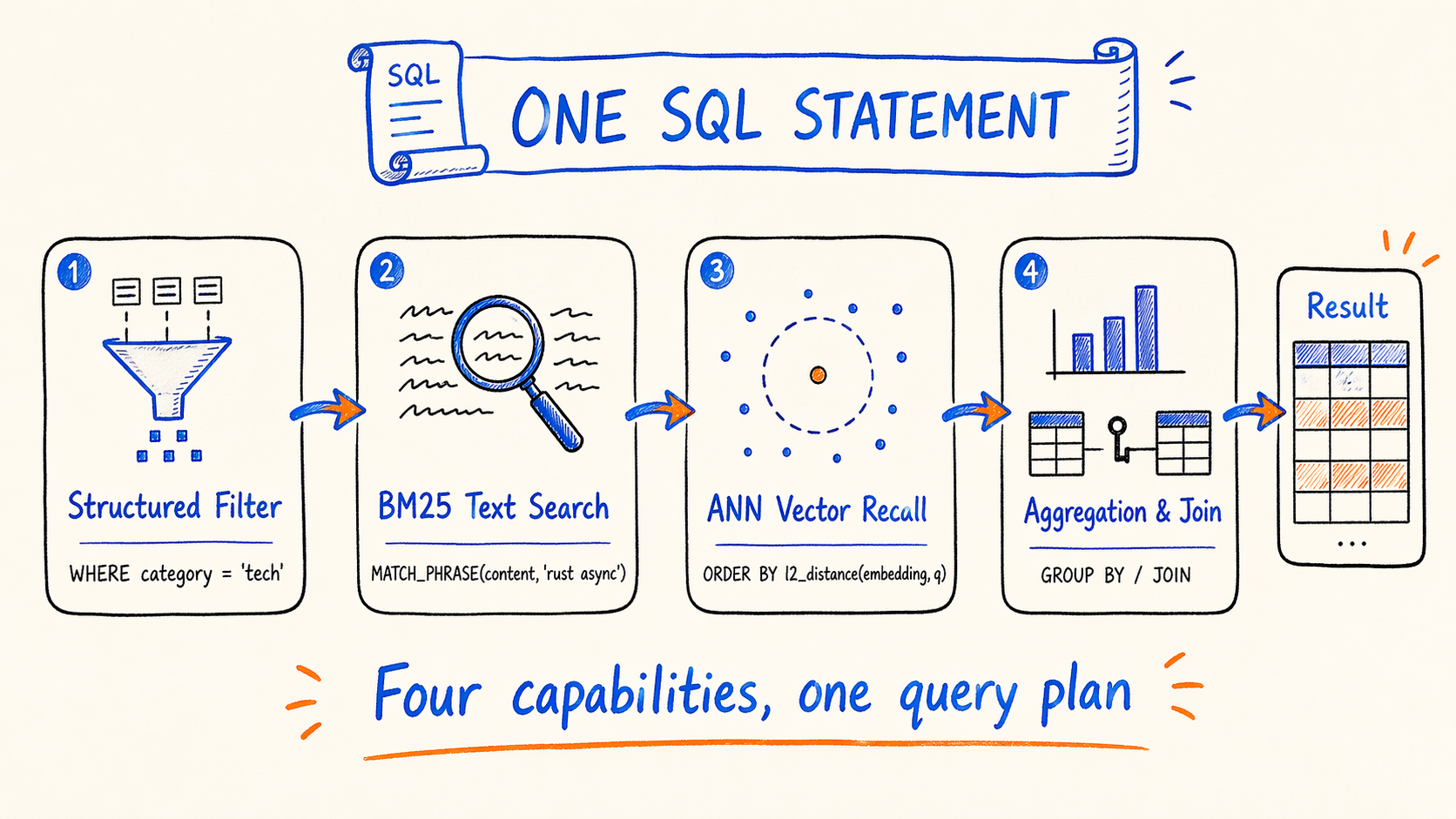
That set of features means hybrid search in a single SQL statement:
- Structured filtering (
WHERE category = 'tech' AND created_at > '2026-01-01') - BM25 text search (
MATCH_PHRASE(content, 'rust async')) - ANN vector recall (
ORDER BY l2_distance(embedding, query_vec) LIMIT 10) - Standard SQL aggregation, sorting, and joins against other tables
Pure vector databases (LanceDB included) usually don’t have full OLAP capabilities, so they can’t express this pipeline in one SQL statement.
3.2 What Lance brings on the data side
Engine features aren’t enough on their own. AI and ML pipelines generate data from sources like:
- Datasets produced by Ray and PyTorch training
- Vector tables in LanceDB
- Intermediate outputs from embedding pipelines
Most of this data lands as Lance files. Re-importing it into Doris would mean a second copy of storage, a sync pipeline to maintain, and losing Lance’s native versioning.
Reading Lance directly gives us:
- Native vector index files that complement Doris’s built-in vector indexes
- Dataset-level versioning and time travel
- Efficient columnar representation for multimodal fields
- Interop with the Ray, LanceDB, and PyTorch ecosystems
Lance handles the data layout, Doris handles the SQL on top.
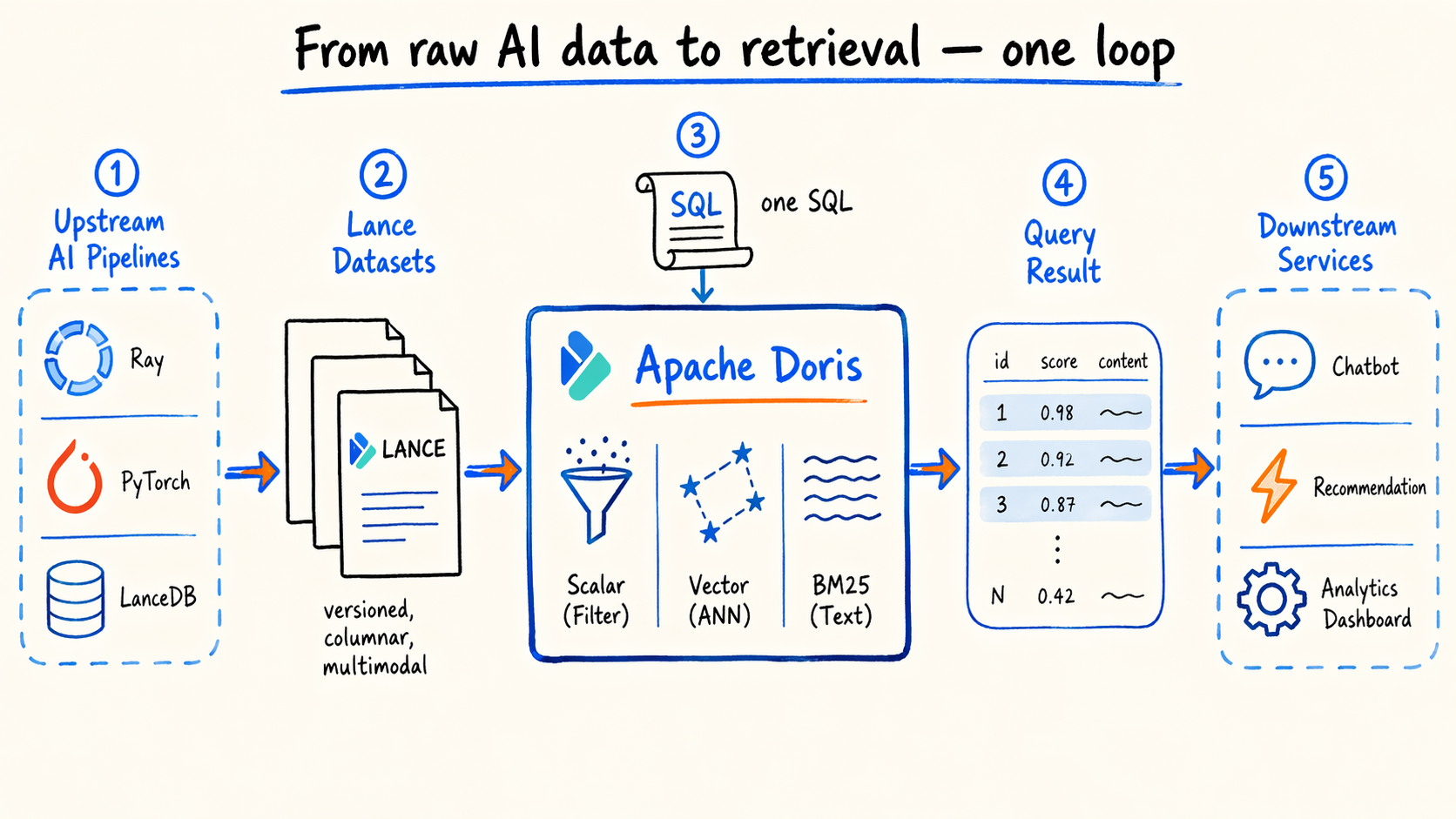
3.3 The end-to-end loop
From a user’s point of view: Ray and LanceDB training produce Lance datasets → Doris reads them directly → one SQL statement handles scalar filtering, vector recall, full-text search, and joins → downstream services consume the result.
From an engineering point of view: this is what the open lakehouse approach looks like applied to AI data. Formats are formats, engines are engines. Doris handles SQL on open formats, Lance handles AI data layout and versioning.
4. The integration problem: Rust meets C++
lance-rs is Rust. Doris BE is C++. They can’t call each other directly. We had two realistic options, and only one was actually realistic.
Option A: rewrite a Lance reader in C++
Lance is still evolving — the format spec, the index algorithms, the version protocol all change. A C++ rewrite means chasing every upstream Rust change indefinitely. That’s a lot of maintenance, and staying in sync is genuinely hard.
Option B: call Rust directly from C++
More direct. No extra layer, no extra runtime. But it raises three questions:
- How does data cross the language boundary? Rust and C++ objects don’t share memory layouts, and marshaling complex nested structures across an FFI is expensive if you do it yourself.
- How do the async models connect? Lance’s IO runs on Tokio; Doris BE uses a synchronous thread-pool model. Both need to live in the same process.
- How do the build systems meet? Cargo and CMake are independent, and
cargo buildoutput has to feed into Doris’s CMake build.
The next section is about the answers.
5. How it’s actually built: a thin FFI layer over Arrow
5.1 Overall shape
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
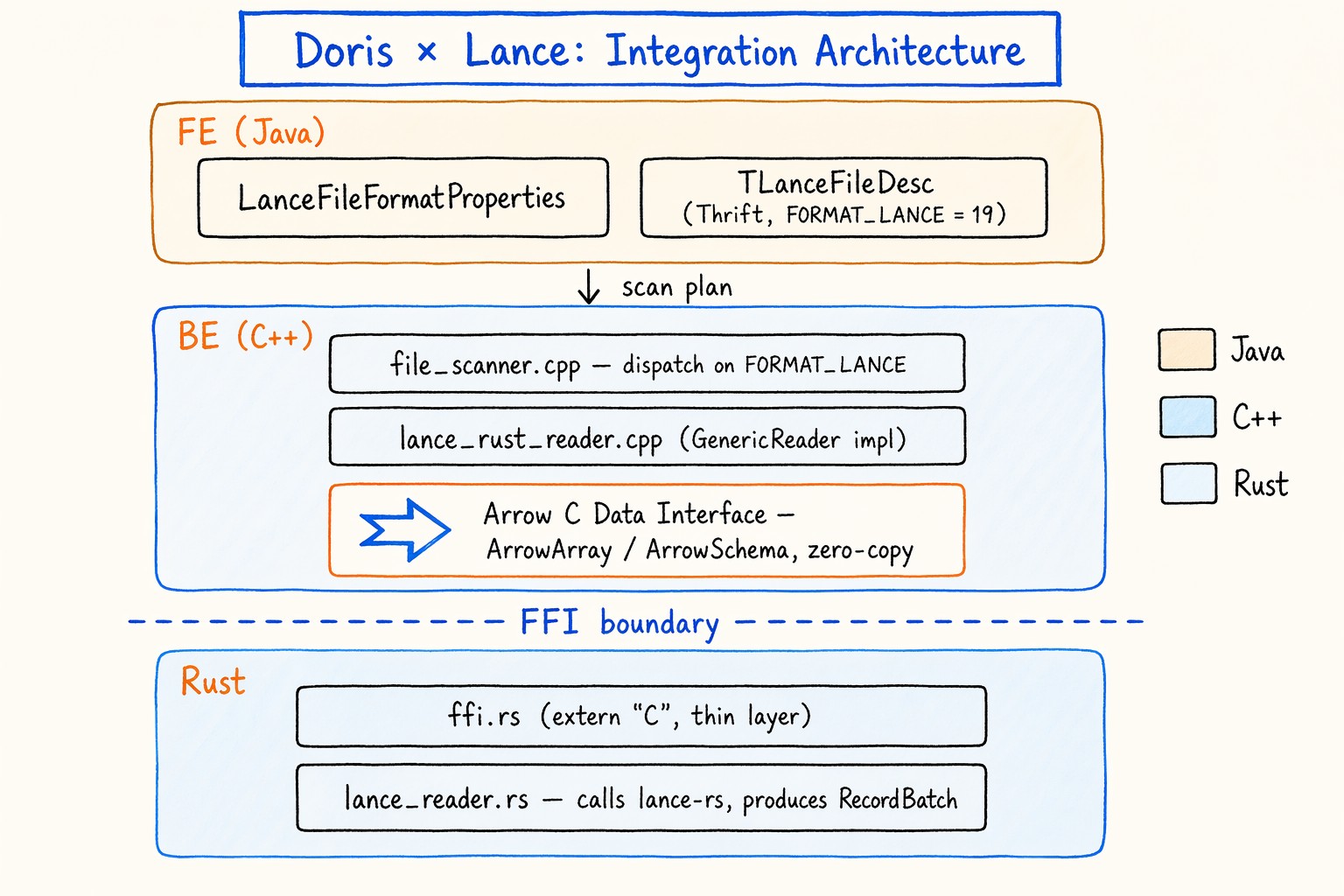
┌──────────────────────────────────────────────────────────────────┐
│ FE (Java) │
│ LanceFileFormatProperties │
│ TLanceFileDesc (Thrift, FORMAT_LANCE = 19) │
└────────────────────────────┬─────────────────────────────────────┘
│ scan plan
▼
┌──────────────────────────────────────────────────────────────────┐
│ BE (C++) │
│ file_scanner.cpp ── dispatch on FORMAT_LANCE │
│ │ │
│ ▼ │
│ lance_rust_reader.cpp (GenericReader impl) │
│ │ │
│ │ Arrow C Data Interface │
│ │ (ArrowArray / ArrowSchema, zero-copy) │
│ ▼ │
│ ── FFI boundary ──────────────────────────────────── │
│ │ │
│ ▼ │
│ ffi.rs (extern "C", thin layer) │
│ │ │
│ ▼ │
│ lance_reader.rs (calls lance-rs, produces RecordBatch) │
└──────────────────────────────────────────────────────────────────┘
The pieces:
- FE side: adds the
FORMAT_LANCEenum and theTLanceFileDescThrift struct, producing scan plans tagged for Lance. - BE side:
lance_rust_reader.cppis aGenericReaderimplementation that consumes data passed in via the Arrow C Data Interface. - FFI layer: a thin
ffi.rscontaining onlyextern "C"functions. Configuration goes in, Arrow C structs come out. - Rust implementation:
lance_reader.rsis where the actuallance-rscalls happen. - Build: Corrosion feeds Cargo’s static library output into CMake.
Each layer answers one of the questions from section 4.
5.2 Data plane: Arrow C Data Interface
The hardest part of any FFI is passing complex data across languages.
A Lance RecordBatch can contain something like List<Struct<field1: String, field2: List<Int64>>>. If we defined our own extern "C" structs, both Rust and C++ would need matching marshaling code, and every schema change would require synchronized edits on both sides. That’s exactly the maintenance tax we were trying to avoid.
The Arrow community already solved this with the Arrow C Data Interface.
It’s a cross-language ABI with two POD structs — ArrowArray and ArrowSchema — each carrying a release callback for lifetime management. Three things about it matter here:
- Zero-copy. Buffer pointers pass directly, no
memcpy. - Already a de-facto standard.
arrow-rsproducesFFI_ArrowArraynatively,arrow-cppconsumes it natively. - Compatible with what Doris already does. Arrow-to-Doris-Block conversion already lives in Doris’s vectorized execution.
The complexity of data-type representation stays inside Arrow’s own spec. Rust and C++ just handle pointers and lifetimes. The marshaling work that would otherwise be duplicated in both projects gets handed off to shared infrastructure.
![]()
5.3 Async: block_on plus a single-threaded Tokio
lance-rs is built on Tokio, and every IO call (especially S3 reads) is an async fn. Doris BE uses a synchronous thread-pool model, and the caller is a plain C++ thread. Both worlds have to live in the same process.
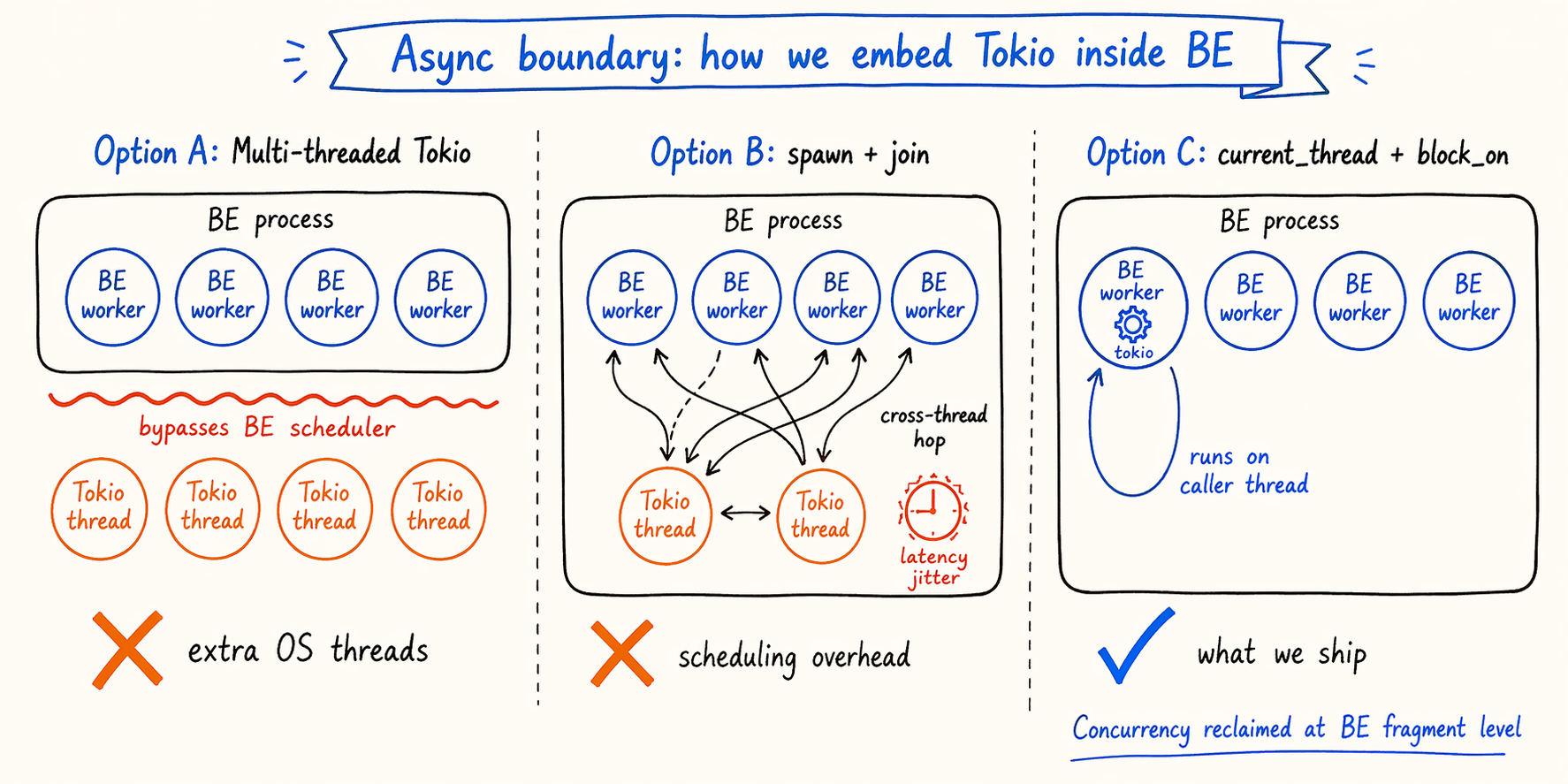
Two obvious options don’t quite fit:
- A multi-threaded Tokio runtime adds OS threads inside BE that bypass BE’s own scheduler, which a thread-sensitive query engine is unhappy about.
tokio::spawn+joinon every call adds cross-thread hops and scheduling overhead, which shows up as latency jitter.
What we do instead: a single-threaded Tokio runtime with block_on.
1
2
3
4
5
6
7
// simplified sketch
let runtime = tokio::runtime::Builder::new_current_thread()
.enable_all()
.build()?;
let result = runtime.block_on(async {
dataset.scan().try_into_batch().await
})?;
What this gets us:
- No extra OS threads. The
current_threadruntime runs on the calling thread, which is BE’s own worker. - BE’s scheduler doesn’t need to know any of this is happening. From outside, it looks like a normal synchronous C++ call.
- The cost: a single-threaded runtime suppresses the IO concurrency Lance could otherwise exploit.
That last point is a real trade-off. We reclaim the lost concurrency at a different layer — BE can split a Lance dataset into multiple fragment-level scan ranges, and several worker threads read in parallel. The concurrency unit lives on the BE side, not inside the runtime, which lines up with how Doris already parallelizes work.
More generally, the pattern is: async stays contained. The external interface is synchronous, the async runtime lives inside, and the two don’t interfere.
5.4 Build: Corrosion
The third question is build-system integration.
You can wire this up by hand in CMake: add_custom_command to invoke cargo build, manual handling for Debug/Release, target triples, and static library paths. It works. It’s not something I’d want to maintain for years.
We use Corrosion instead, a community project dedicated to CMake/Cargo integration. It handles:
- Reading
Cargo.tomland turning each declared crate into a CMake target - Debug/Release mapping
- Target-triple handling for cross-compilation
- Static library linking and dependency propagation
The practical outcome is that one rust.cmake file contains all the Rust build differences, and the main Doris build system barely changes. For a CMake project Doris’s size, that kind of minimally invasive integration matters.
5.5 Opt-in by default
The release path uses two switches:
- Compile-time:
BUILD_RUST_READERS=OFFby default, so existing users don’t notice anything. - Enabling the build:
BUILD_RUST_READERS=ON ./build.sh --be, which requires a Rust toolchain. - Runtime: the
enable_rust_lance_readersession variable.
The two switches let new capabilities land on trunk safely without affecting current users.
5.6 Binary size
Rust has a cost here:
- The
libdoris_native.astatic library is around 430MB. - After LTO, the final
doris_begrows by 50 to 80MB.
The growth comes from monomorphization (generics producing code copies), the full Tokio runtime being linked in, and the complete dependency trees for Arrow and Lance.
It’s worth looking at this number in context. Today the Java side of a Doris release approaches 1GB: Hadoop client, iceberg-java, delta-spark, parquet-mr, the JVM runtime, and the associated JNI glue. A large chunk of that exists only so a small piece of JVM code inside FE or BE can read specific lake formats.
As the Rust ecosystem takes on more of these jobs — iceberg-rust, delta-rs, and hudi-rs are the candidates after Lance — every replaced Java reader takes its JARs and glue code with it.
From that angle, the 50 to 80MB from Lance reads less like pure overhead and more like a one-time infrastructure cost. On top of that baseline, every additional Rust component adds only marginal cost — shared Tokio, shared Arrow, shared FFI framework. Over time, the release bundle may actually shrink.

5.7 What’s not done yet
The first version gets the critical path working. Production readiness still needs more work, and each of these is open to community contribution:
- IO concurrency. Under the current single-threaded runtime +
block_onmodel, Lance’s internal IO concurrency is suppressed. BE needs fragment-level parallel scan ranges to bring it back. OpenDAL as a unified IO abstraction is worth looking at too. - Cache integration. Lance reads from S3 bypass Doris’s
BlockFileCacheentirely, so remote reads skip local SSD caching. Rust-side IO needs to route through Doris’s existing cache layer. - Vector and FTS index cache. Lance reloads vector and full-text indexes on every query today. A session-level
IndexCacheshared across queries would fix this. - Filter, vector, and FTS pushdown.
LanceReaderConfigreservesfilter,vector_search, andfull_text_searchfields on the Rust side, but the FE planner doesn’t populate them yet.WHERE, ANN, and BM25 all need to push down into thelance-rsscanner. - Performance benchmarks. Most of what we have so far is functional verification. We still need end-to-end comparisons against Parquet and the native Iceberg reader, plus benchmarks targeting multimodal workloads.
- Observability. Rust-side logs and metrics are separate from Doris’s system. They need to integrate with
QueryProfile,RuntimeProfile, and slow-log tooling. Panic capture and backtrace exposure also need work. - Error semantics. The mapping from Rust
Resultandanyhow::Errorthrough FFI into Doris’sStatusis coarse today. We need finer-grained error codes. - Build and release. The Rust toolchain is a build-time dependency, and CI needs to include Rust builds in the regular pipeline. Cross-compilation and musl static linking are also on the list.
None of these are hotfix defects. They’re the next steps along this path.
6. Running a Lance query in 5 minutes
Prerequisites: a BE compiled with BUILD_RUST_READERS=ON, and the enable_rust_lance_reader session variable turned on.
Example 1: local file.
1
2
3
4
5
SELECT * FROM local(
"file_path" = "data/my_dataset.lance/data/fragment.lance",
"backend_id" = "<BE id>",
"format" = "lance"
) ORDER BY id LIMIT 10;
Example 2: S3.
1
2
3
4
5
6
7
8
SELECT count(*), avg(score) FROM s3(
"uri" = "s3://bucket/embeddings.lance/data/fragment.lance",
"format" = "lance",
"s3.access_key" = "...",
"s3.secret_key" = "...",
"s3.region" = "us-east-1",
"s3.endpoint" = "https://s3.us-east-1.amazonaws.com"
);
What works right now: projections, WHERE, LIMIT, aggregations (SUM, AVG, COUNT), and multi-fragment datasets.
What doesn’t work yet: CREATE CATALOG, filter and vector pushdown, and BlockFileCache integration.
The gaps map directly onto the roadmap in the next section.
7. What’s next
7.1 From a TVF to a full Lance Catalog
The current implementation points at a single .lance file through the s3() or local() TVFs. That’s an MVP — good for demos, validation, and regression tests.
A production form needs a proper Lance Catalog:
CREATE CATALOG lance_cat PROPERTIES (...)attaches a Lance dataset root or a LanceDB instance.SELECT * FROM lance_cat.db.tableshould feel like querying a Doris internal table. Users shouldn’t need to know about fragment counts or file layout.- The FE generates fragment-level scan ranges so several BE workers read in parallel.
- The FE handles predicate and vector pushdown, so
WHEREand ANN conditions reach thelance-rsscanner. - Dataset-level time travel gets first-class syntax:
FOR VERSION AS OF N.
7.2 Reusing the same framework for other Rust components
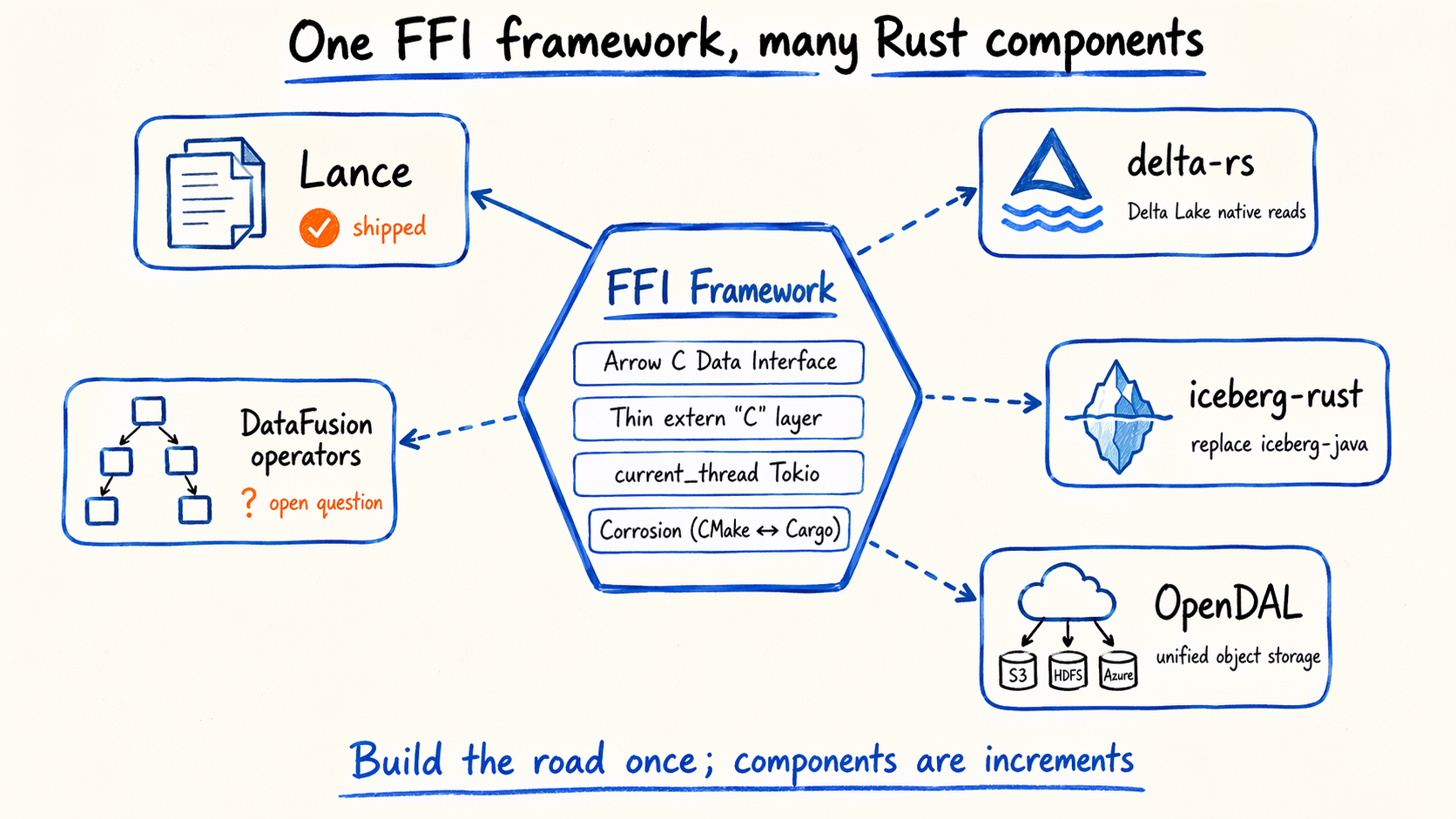
The FFI framework — Arrow C Data Interface + thin FFI layer + single-threaded Tokio + Corrosion — isn’t Lance-specific. It extends naturally to:
- delta-rs: native Delta Lake reads, replacing the current JNI + delta-spark path.
- iceberg-rust: native Iceberg reads, to compare against the current iceberg-java approach.
- OpenDAL: a unified object-storage abstraction to replace the multiple S3, HDFS, and Azure clients inside BE.
- Selected DataFusion operators. Whether any are actually worth reusing is an open question for the community.
7.3 What we expect to gain long-term
If we keep pushing along this path:
- Smaller release bundles, as iceberg, delta, and hudi JNI and JVM dependencies get removed.
- Faster startup and more stable memory — fewer JVM GC hiccups, no JNI crossings.
- Upstream tracking that keeps step with the Rust community’s release cadence, without waiting for Java wrappers to catch up.
One open question while we’re here: could a C++ core engine extended by the Rust ecosystem become a viable shape for the next generation of OLAP engines? I’d be interested to hear what people think — on the PR, in issues, or wherever the discussion happens.
Closing
Lance is one piece of Doris’s multimodal story. Doris’s engine-side features (native ANN, inverted indexes, BM25) plus Lance’s AI-native data layout and versioning mean the path from raw data to retrieval fits into a single SQL statement.
This integration also makes room for the rest of the Rust ecosystem inside Doris’s C++ process. Lance is the first component; more will follow.
PR: https://github.com/apache/doris/pull/62182
Happy to take questions, reviews, or pushback on the PR.